-
2. 애플리케이션 계층공부/컴퓨터 네트워크 2022. 5. 17. 19:36반응형

이 글은 Computer Networking: A Top-Down Approach 7th를 읽고 정리한 글입니다.
1. 네트워크 애플리케이션의 원리
1.1 네트워크 애플리케이션 구조
현재 사용되는 애플리케이션 구조는 클라이언트-서버 구조와 Peer-to-Peer(P2P 구조가 있다.
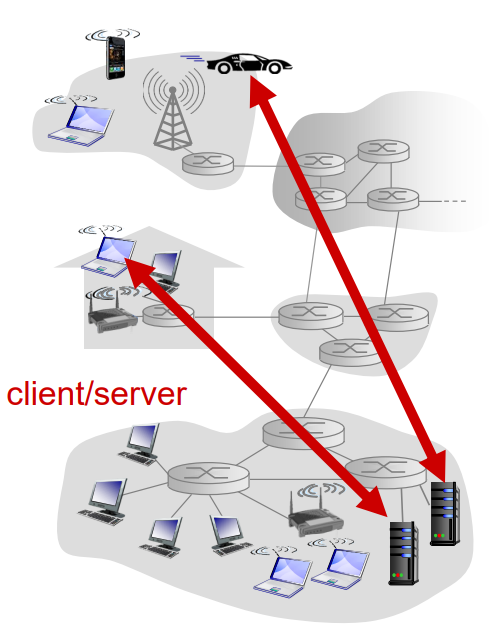
클라이언트-서버 구조
항상 켜져 있는 호스트를 서버라고 부르고, 서버는 클라이언트라는 다른 많은 호스트들의 요청을 받는다.
웹 서버가 클라이언트 호스트로부터 객체를 요청받으면 웹 서버는 클라이언트 호스트로 요청된 객체를 보내어 응답한다.
클라이언트의 특징은 클라이언트끼리 서로 직접적으로 통신을 하지 않고, 클라이언트 호스트는 서버와 다르게 항상 연결되어 있지 않고 가끔씩만 연결된다.서버의 특징은 항상 켜져 있고, 고정 IP 주소라는 잘 알려진 주소를 가지고 있다.
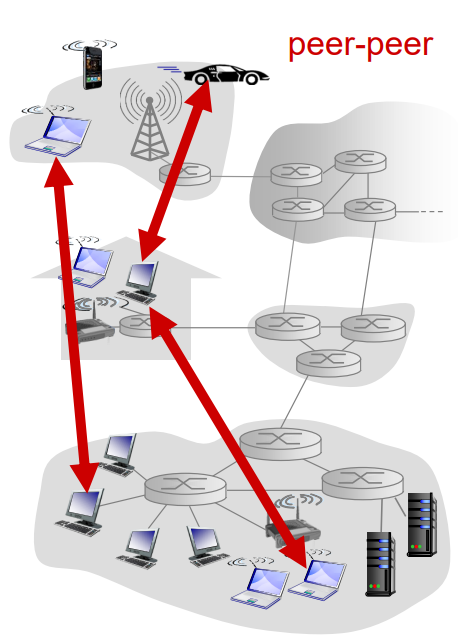
P2P 구조
이 구조는 특정 서버를 통하지 않고 피어(peer)라는 간헐적으로 연결된 호스트 쌍이 서로 직접 통신하도록 한다. 이때 피어는 사용자들이 제어하는 컴퓨터이다.
P2P 구조의 특징은 자가 확장성(self-scalability)이다. 예를 들어 피어가 다른 피어에게 파일을 요구해 얻으면, 그 피어도 이제 다른 피어들에게 파일을 줄 수 있는 것을 반복할 수 있다. 거기다가 클라이언트-서버 구조와 다르게 거대한 서버가 필요없기 때문에 비용이 효율적이다.
대표적인 예시로 토렌트가 있다.
1.2 프로세스 간 통신
실행중인 프로그램을 프로세스라고 부른다. (운영체제 참고)
종단 시스템에서 프로세스는 네트워크를 통한 메시지 교환으로 서로 통신을 한다.
세션: 클라이언트별로 각각의 정보를 서버에 저장하는 기술
클라이언트 프로세스: 세션에서 통신을 초기화하는 프로세스 (ex. 웹에 들어가 서버에 요청하는 것)
서버 프로세스: 세션을 시작하기 위해 접속을 기다리는 프로세스 (ex. 클라이언트가 웹에서 어떤 행동을 하길 기다리는 것)
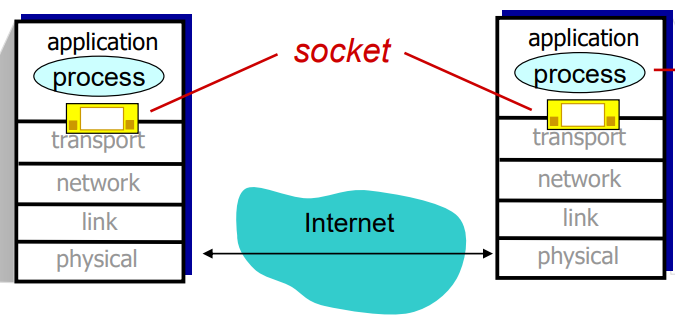
프로세스는 소켓을 통해 네트워크로 메시지를 보내고 받는다.
이때 소켓을 출입구라고 생각하면 쉽다.
인터넷에서 호스트는 32비트 IP 주소로 식별되고, 한 호스트가 다양한 네트워크 응용을 수행할 수 있어서 16비트인 포트 번호를 사용한다.
몇몇 포트 번호는 계속 사용되기 때문에 고정적으로 할당이 되어 있다.
1.3 트랜스포트 계층에서 애플리케이션 계층에 제공하는 서비스
위에 있는 소켓 사진을 보면 알다시피 소켓이 애플리케이션 계층과 트랜스포트 계층 사이에 있다는 것을 알 수 있다.
정확한 메시지 전달 과정을 말하자면 애플리케이션 층에서 메시지를 소켓에 보내지만, 메시지를 받을 때는 트랜스포트 층에서 메시지를 소켓으로 이동 시켜야 한다.
트랜스포트 계층이 애플리케이션 계층에 제공할 수 있는 서비스는 아래와 같다.
1) 신뢰적 데이터 전송
패킷들은 네트워크 내에서 손실될 수 있는데, 트랜스포트 계층은 데이터가 오류 없이 보낼 수 있는 프로세스 간 신뢰적 데이터 전송을 제공한다.
2) 처리량
애플리케이션이 r bits/sec의 보장된 처리율을 요구하면 트랜스포스 계층은 항상 적어도 r bps를 보장하는 것이다.
이런 보장된 처리율은 많이 쓰이는데, 특히 음성 데이터의 경우 32kbps로 음성을 인코딩을 해야하지만 32kbps를 보장하지 못하면 소리가 제대로 들리지 않을 것이다.
3) 시간
트랜스포트 계층은 시간 보장을 제공할 수 있다. 여기서 시간 보장이란 애플리케이션 계층이 t msec 내에 데이터를 보내야한다고 요구하는 것을 보장한다는 것이다.4) 보안애플리케이션 계층에 데이터 암호화 혹은 해독 등의 보안을 제공할 수 있다.
1.4 인터넷 전송 프로토콜이 제공하는 서비스
인터넷은 TCP와 UDP라는 2개의 전송 프로토콜을 애플리케이션 계층에 제공한다.
1. TCP
- 연결지향형 서비스 (3-way handshaking)
- 신뢰적인 데이터 전송 서비스 (데이터를 오류 없이 올바른 순서로 전달함)
- 혼잡 제어
- 흐름 제어
- 패킷 오버헤드 회피
- 데이터를 안정적으로 보내기 위해 속도를 어느정도 타협함
2. UDP
- 비연결형 서비스
- 비신뢰적 데이터 전송 서비스
- 혼잡 제어 미사용
- 데이터를 빠르게 보내기 위해 기능들을 포기함
2. Web, HTTP
2.1 HTTP 개요
- 웹 페이지는 객체들로 구성된다. (객체 = HTML, JPEG, GIF, ...)
- 웹 페이지는 기본 HTML 파일과 여러 참조 객체로 구성된다.
- 객체들은 URL을 가지고 있다.
URL은 2개의 서버의 호스트 네임과 객체의 경로 이름을 가지고 있는데, 아래 예시를 살펴보자
http://www.someSchool.edu/someDepartment/picture.gif
이런 URL이 있다면 http://www.someSchool.edu는 호스트 네임이고, someDepartment.picture.gif는 경로 이름이다.
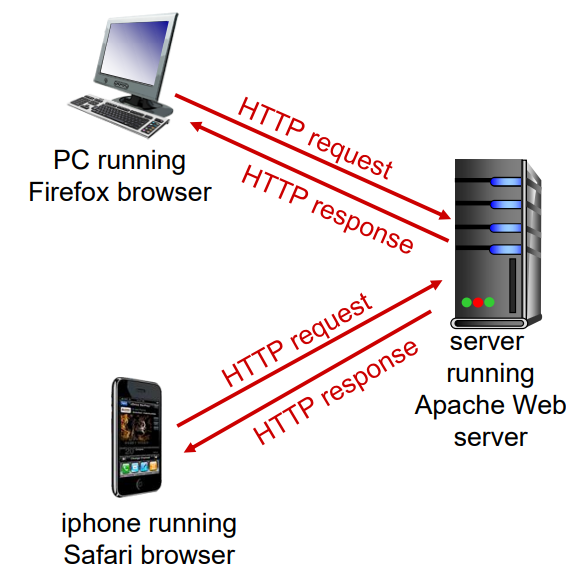
사용자가 웹 페이지를 요청할 때, 브라우저는 페이지 내부의 객체에 대한 HTTP 요청 메시지를 서버에게 보낸다. 그러면 서버는 요청을 수신하고 객체를 포함하는 HTTP 응답 메시지로 응답한다.
자세한 과정을 살펴보자
HTTP는 TCP를 전송 프로토콜로 사용하고, HTTP 클라이언트는 먼저 서버에 TCP 연결을 시작한다.
연결이 이루어지면 브라우저와 서버 프로세스는 각자의 소켓을 통해 TCP로 접속을 한다.
클라이언트는 HTTP 요청 메시지를 소켓 인터페이스로 보내고, 소켓 인터페이스로부터 HTTP 응답 메시지를 받는다.
이때 주의할 점은 서버는 클라이언트의 상태 정보를 저장해두지 않는다. 쉽게 설명하면 이전에 한 일을 잊어버린다는 것이다. 그래서 같은 클라이언트가 다른 시간대에 같은 작업을 요청하면 해당 요청을 수신하여 객체를 또 보내게 된다.
이런 점 때문에 HTTP를 무상태 프로토콜(stateless protocol)이라고 한다.
2.2 비지속 연결과 지속 연결
클라이언트-서버 상호작용중 여러 번의 반복된 상호작용에서 TCP 연결을 어떻게 보내야할지 의문점이 생긴다.
예를 들어 10개의 파일을 한 번에 다운 받는다고 요청을 했을 경우, 클라이언트의 기준에서는 한 번에 10개 파일을 요청했다고 생각하지만, 실제로는 1개의 파일을 요구하고 응답 받는 작업을 10번 반복하는 것이다.
여기서 각각의 요청을 각각의 TCP 연결로 보내야 할지, 아니면 10개의 요청을 1개의 TCP 연결로 해야할지 고민이 생긴다.
이때 전자처럼 각각의 TCP 연결로 한다면 비지속 연결(non-persistent)라고 하고, 1개의 TCP 연결로 모든 작업을 처리하면 지속 연결(persistent)라고 한다.
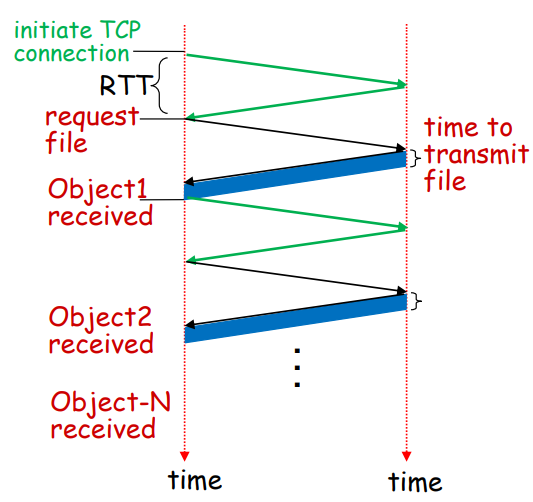
비지속 연결 HTTP - 한 번 다운 받을 때마다 TCP 연결을 계속한다.
만약 N개의 파일을 다운 받는다고 하면 (2*RTT + file transmit time) * N이 된다.
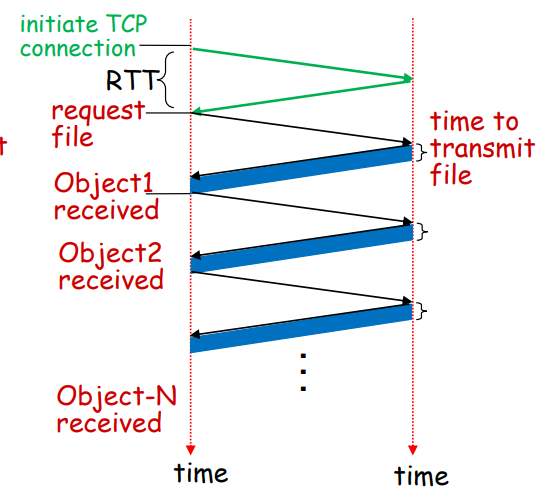
지속 연결 HTTP - 한 번의 TCP 연결로 모든 파일을 다운 받는다.
만약 N개의 파일을 다운 받는다고 하면 RTT + (RTT + file transmit time) * N이 된다.
2.3 HTTP 메시지 포맷 - HTTP 요청 메시지
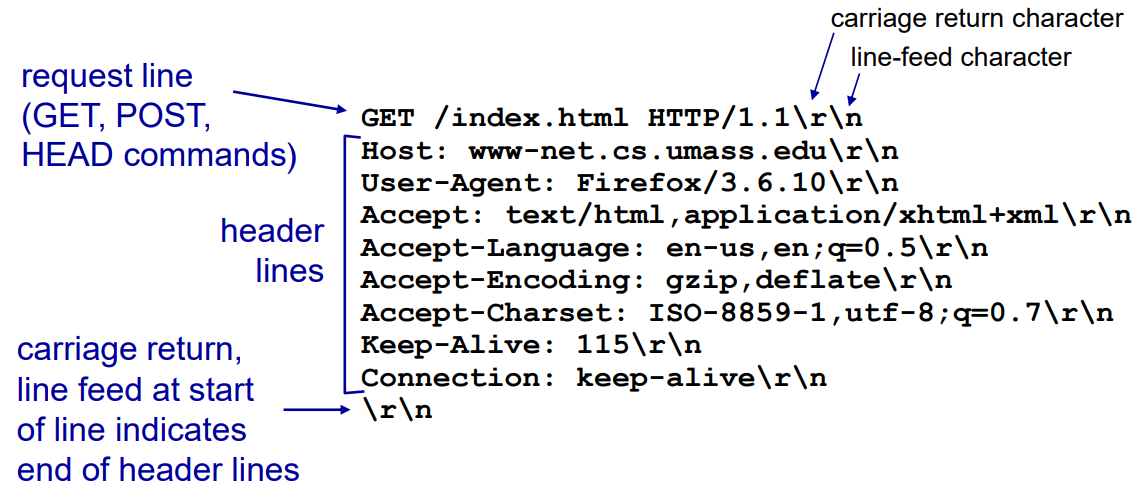
요청 라인
method 필드 + URL 필드 + HTTP 버전 필드
1. method 필드: GET, POST, HEAD, PUT, PATCH, DELETE 등이 있다.
2. URL 필드: method를 어디에 적용을 해야하는지에 대해 적혀 있다.
3. HTTP 버전 필드: 단순히 HTTP 버전에 대한 정보가 적혀있다.
헤더 라인
1. Host는 호스트를 명시하는 것이다.
2. User-Agent는 서버에 요청을 하는 브라우저 타입을 명시한다. (여기서는 파이어폭스 브라우저가 요청을 하고 있다.)
3. Accept의 경우엔 요청에 대한 응답이 가능한 Content-Type을 명시한다.
4. Accept-Language는 응답할 때 언어를 원하고 있는지 명시한다.
5. Accept-Encoding은 클라이언트가 이해 가능한 압축 알고리즘을 명시한다.
6. Accept-Charset은 클라이언트가 요구하는 Character set을 의미한다.
7. Keep-Alive는 특정 시간 동안 최대 요청 수를 의미한다. (매 번 비지속 연결을 하면 자원 낭비라서 특정 시간동안 지속 연결)
8. Connection은 어떻게 연결을 할 것인지에 대한 것을 명시한다.
Method
1. GET: 서버에 리소스를 요청할 때 사용함. 반환 값에 HTML 본문을 읽어옴2. HEAD: GET과 비슷하지만 반환 값에 HTML 본문을 읽어오지 않음3. POST: 서버에 리소스를 생성하기 위해 사용한다.4. PUT: 서버의 전체 리소스를 변경하기 위해 사용한다.5. PATCH: 서버의 특정 리소스를 변경하기 위해 사용한다. 6. DELETE: 특정 리소스를 삭제할 떄 사용한다.
2.4 HTTP 메시지 포맷 - HTTP 응답 메시지
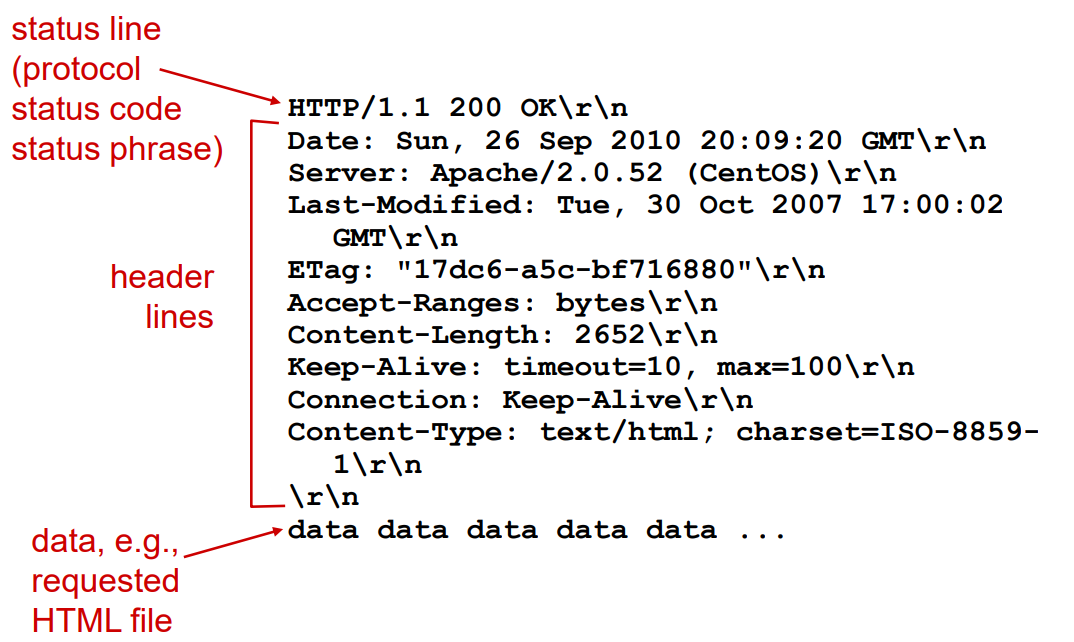
HTTP 응답 메시지는 상태 라인(status line), 헤더 라인(header line), 개체 몸체(entity body)로 이루어져 있다.
상태 라인
HTTP 버전 필드 + 상태 코드 + 상태 메시지
1. HTTP 버전 필드: HTTP 버전
2. 상태 코드: 숫자로 나타낸다. 백의 자리 수가 다를 때마다 다른 것을 의미한다.
3. 상태 메시지: 상태 코드가 무슨 뜻을 의미하는지 나타낸다.
헤더 라인
1. Date: HTTP 응답이 서버에 의해 생성되고 보낸 날짜와 시간을 나타낸다.
2. Server: 어떤 서버로 만들어졌는지 나타낸다. (여기서 CentOS에서 아파치 웹 서버에 의해 만들어졌음을 의미한다.)
3. Last-Modified: 객체가 생성되거나 마지막으로 수정된 시간과 날짜를 나타낸다.
4. ETag: 특정 URL의 특정 리소스에 대한 고유한 번호
5. Accept-Ranges: 값의 범위를 설정할 때 사용함 (Content-Length와 이어짐)
6. Content-Length: 메시지 본문의 길이를 뜻한다 (2652는 2652 bytes를 의미한다.)
7. Content-Type: 지금 보내는 메시지가 어떤 타입인지 뜻한다.
개체 몸체
메시지 본문을 뜻하고, 여기에 데이터들이 있다.
대표적인 상태 코드와 상태 메시지
1. 200 OK: 요청이 성공되었고, 정보가 응답으로 보내졌다.
2. 301 Moved Permanently: URL이 바뀌었다는 뜻으로 응답 메시지에 Location에 이동된 URL이 나와있다.
3. 400 Bad Request: 서버가 요청을 할 수 없다는 오류 코드이다.
4. 404 Not Found: 요청 문서가 서버에 존재하지 않다는 뜻이다.
5. 505 HTTP Version Not Supported: 요청 HTTP 프로토콜 버전을 서버가 지원하지 않다는 뜻이다.
2.5 쿠키
위 2.1에서 서버는 클라이언트의 상태 정보를 저장하지 않기 때문에 HTTP를 무상태 프로토콜(stateless protocol)이라고 했다.
관리자 페이지 같이 사용자 접속을 제한하거나 사용자에 따라 콘텐츠를 제공하기를 원하므로 웹 사이트가 사용자를 확인해야 한다. 이때 HTTP는 쿠키(cookie)를 사용한다.
쿠기 기술은 네 가지 요소를 지원한다.
1) HTTP 응답 메시지 쿠키 헤더 라인
2) HTTP 요청 메시지 쿠키 헤더 라인
3) 사용자의 브라우저에 사용자 종단 시스템과 관리를 지속하는 쿠키 파일
4) 웹 사이트의 백엔드 데이터 베이스
우리가 웹 페이지에 로그인을 하고 인터넷 창을 꺼두었는데, 다시 인터넷을 켜서 해당 사이트에 들어가보면 로그인이 되어 있는 것을 알 수 있다. 이것을 유지하는 기술이 쿠키이다.
쿠키는 예시를 통해 설명하는 것이 매우 좋다.
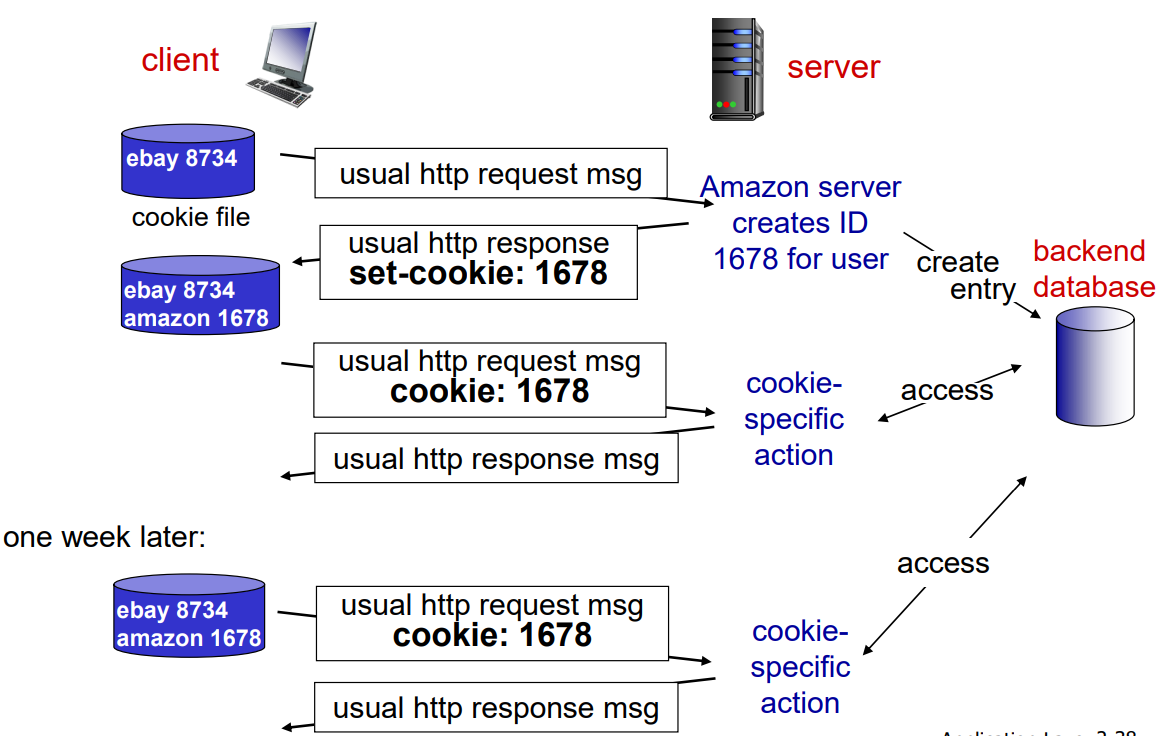
1) 클라이언트는 ebay에 대한 쿠키 파일을 가지고 있는 상태에서 아마존에 들어간다.
2) 이때 서버는 클라이언트에 식별 번호를 부여하여 백엔드 데이터베이스 안에 엔트리를 만든다.
3) 이후 HTTP 응답 메시지에 Set-cookies에 식별 번호를 보내 클라이언트가 1678를 저장하게 만든다.
4) 클라이언트가 나중에 다시 아마존에 접속할 때, 쿠키 값도 같이 보내면 아마존은 해당 클라이언트의 기호 제품을 추천한다.
5) 일주일 뒤에 다시 아마존에 접속해도 쿠키 값을 같이 보내기 때문에 아마존은 또 클라리언트의 기호 제품을 추천하게 된다.
2.6 웹 캐싱
웹 캐시는 프록시 서버(proxy server)라고도 하며 원래 서버를 대신하여 HTTP 요구를 충족시켜주는 네트워크 개체이다.
웹 캐시는 자체적으로 저장 디스크를 가지고 있어서 최근 호출된 객체의 사본을 저장 및 보존한다.
밑의 예시 그림을 통해 더 자세히 이해해보자
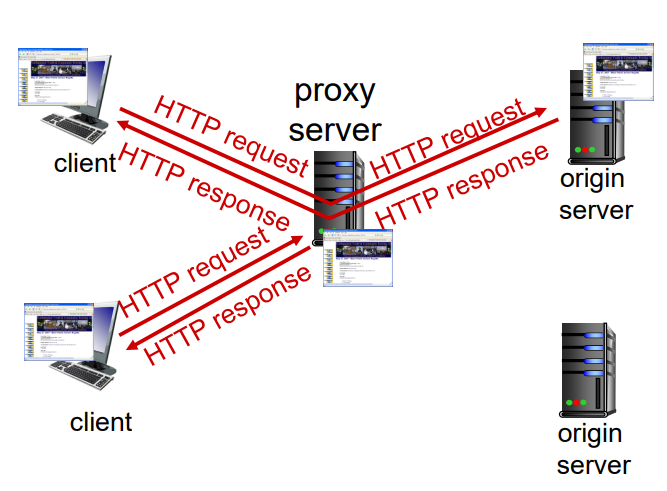
1. 사진에서 위에 있는 클라이언트가 웹 캐시와 TCP연결을 설정하고 HTTP 요청을 보낸다.
2. 웹 캐시는 요청한 객체가 자신에게 저장되어 있는지 확인해보고, 없으면 원래 서버에 요청을 보낸다.
3. 원래 서버가 웹 캐시에 응답을 보내고, 웹 캐시는 해당 객체를 자신의 디스크에 저장한다.
4. 이후 클라이언트에 응답 메시지를 보낸다.
5. 밑에 있는 클라이언트가 웹 캐시와 TCP 연결을 설정하고 HTTP 요청을 보낸다.
6. 웹 캐시는 요청한 객체가 자신에게 저장이 되어 있으므로 클라이언트에게 바로 응답 메시지를 보낸다.
웹 캐싱 장점
- 클라이언트의 요구에 대한 응답 시간을 줄일 수 있다. (웹 캐시를 여러 개 두면 되므로)
- 웹 트래픽을 대폭 줄일 수 있다. (웹 캐시를 사용해 트래픽을 분산하므로)
- 트래픽이 줄어들기 때문에 웹 캐시를 사용하지 않고 서버를 업그레이드 하는 것보다 비용이 적게 든다.
웹 캐싱 단점 - 조건부 GET
웹 캐싱은 클라이언트가 기다리는 시간을 줄일 수 있지만, 캐시 내부에 있는 복사본을 전달해주기 때문에 만약 데이터가 업데이트 했더라도 업데이트 이전의 값을 돌려줄 가능성이 존재한다.
그래서 HTTP에서는 조건부 GET이라는 객체가 최신의 것임을 확인하는 방법을 지원해주는데, 클라이언트의 요청 메시지를 대신해 프록시 캐시가 원래 서버에 요청메시지를 보낸다. 이때 GET 방식을 사용하고, If-Modified-Since: 헤더 라인에 클라이언트가 가지고 있던 데이터의 날짜를 넣어준다.
만약 서버에 있는 데이터가 바뀌지 않았다면 본문 없이 304 Not Modified만 보낼 것이고, 만약 데이터가 업데이트가 됐었다면 200 OK를 보내고 본문에 데이터를 같이 보내준다.
여기서 304 Not Modified만 보내고, 본문이 없는 이유는 당연할 수도 있겠지만 어차피 달라지지 않은 데이터를 보내는 것은 대역폭을 낭비하는 것 뿐이고, 무엇보다 지연시간이 더 길어지기 때문이다.
반응형'공부 > 컴퓨터 네트워크' 카테고리의 다른 글
6. 혼잡 제어 (0) 2022.05.24 5. 파이프라인 프로토콜, TCP (0) 2022.05.24 4. 트랜스포트 계층 (0) 2022.05.23 3. e-mail, DNS (0) 2022.05.18 1. 컴퓨터 네트워크와 인터넷 (2) 2022.05.10