-
3. e-mail, DNS공부/컴퓨터 네트워크 2022. 5. 18. 19:48반응형

이 글은 Computer Networking: A Top-Down Approach 7th를 읽고 정리한 글입니다.
1. 인터넷 전자메일
전자메일은 일반 우편처럼 내가 원할 때 메시지를 보내거나 읽을 수 있는 비동기적인 통신 매체이다.
이메일의 주요 요소는 아래와 같다.
1. 사용자 에이전트 (user agent)
2. 메일 서버 (mail server)
3. SMTP (Simple Mail Transfer Protocol)
사용자 에이전트
먼저 사용자 에이전트는 사용자가 메시지를 읽고, 응답하고, 전달하고, 구성하게 해준다.
사용자가 메시지 작성을 끝내면, 사용자 에이전트는 메시지를 메일 서버로 보내고 메시지는 메일 서버의 출력 메시지 큐에 들어간다. 그리고 메일을 받은 사람이 메일을 읽고 싶으면 그 사용자의 에이전트가 메일 서버에 있는 메일박스에서 메시지를 가져온다.
메일 서버
각 사용자는 메일 서버 안에 메일박스를 가지고 있는데, 메일박스는 사용자에게 온 메시지를 유지하고 관리한다.
사용자가 전자 메일에 있는 메일을 보려면, 메일 서버는 사용자 아이디와 비밀번호를 이용하여 밥을 인증한다.
이때 A사용자가 B사용자에게 메일을 보내고 싶은데 보낼 수 없는 상태라면, A사용자의 메일 서버는 메시지 큐에 메일을 저장해두고, 주기적으로 B사용자의 메일 서버에 보내는 것을 시도한다.
SMTP
메일을 전송하는데 TCP처럼 신뢰적인 데이터 전송 서비스를 제공한다.
SMTP의 서버와 클라이언트는 모두 메일 서버에서 수행된다.
메일 서버가 상대 메일 서버로 메일을 보낼 때는 SMTP의 클라이언트로 동작하지만, 메일 서버가 상대 메일 서버로부터 메일을 받는 것은 SMTP 서버로 동작한다. (Socket, 애플리케이션 계층, 트랜스포트 계층과 비슷하다)
1.1 SMTP
SMTP는 송신자의 메일 서버로부터 수신자의 메일 서버로 메시지를 전송한다.
아래 예시를 통해 작동 방식에 대해 알아보자
1. 앨리스는 밥의 전자메일 주소와 메시지를 작성하고, 사용자 에이전트에게 메시지를 보내라고 명령한다.
2. 앨리스의 사용자 에이전트는 메시지를 엘리스의 메일 서버에 보낸다. 그러면 메시지는 메시지 큐에 놓인다.
3. 앨리스의 메일 서버에서 동작하는 SMTP의 클라이언트는 메시지 큐에 있는 메시지를 보고, 밥의 메일 서버에서 동작하는 SMTP 서버에게 TCP 연결을 설정한다.
4. SMTP 핸드셰이킹 이후 SMTP 클라이언트는 메시지를 TCP 연결로 보낸다.
5. 밥의 메일 서버에서 동작하는 SMTP 서버는 메시지를 밥의 메일 박스에 놓는다.
6. 밥은 메시지를 읽고 싶을 때 사용자 에이전트에게 명령한다.
이때 SMTP는 중간 메일 서버를 사용하지 않고, 바로 전달을 하는 것이 특징이다.
1.2 HTTP와의 비교
[공통점 1]
HTTP는 웹 서버로부터 브라우저로 객체를 전송한다.
SMTP는 메일 서버로부터 다른 메일 서버로 메시지를 전송한다.
[공통점 2]
HTTP와 SMTP는 모두 지속 연결을 사용한다.
[차이점 1]
HTTP는 Pull 프로토콜로 서버에 정보를 올리고, 사용자가 서버로부터 정보를 가져오기 위해 HTTP를 사용한다.
SMTP의 경우에는 Push 프로토콜로 송신 메일 서버가 파일을 수신 메일 서버로 전송한다.
[차이점 2]
HTTP는 메시지의 크기가 제한이 없다.
SMTP는 메시지의 몸체를 포함하여 각 메시지가 7비트 ASCII 포맷이어야 한다.
[차이점 3]
HTTP는 각 객체를 캡슐화하여 보낸다.
SMTP는 모든 메시지의 객체를 하나의 메시지로 만들어서 보낸다.
1.3 메일 메시지 포맷

[메시지 헤더]
1. From: 내 이메일 주소
2. To: 상대방 이메일 주소
3. Subject: 메일 제목
[메시지 몸체]
메일 내용
1.4 메일 접속 프로토콜
오늘날의 메일 접속은 클라이언트-서버 구조를 사용한다.
그래서 사용자 에이전트는 수신자의 메일 서버에 메시지를 보내야 하는데, SMTP를 사용해 송신자의 메일 서버를 경유하여 보낸다.
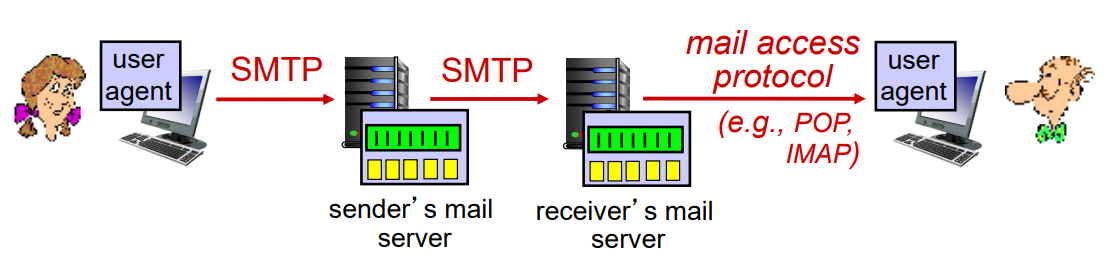
이렇게 두 번의 SMTP를 사용하는 이유는 사용자 에이전트에는 메시지 큐가 없기 때문에 한 번 메일을 보내는데, 밥의 메일 서버가 작동중이지 않으면 그대로 메일이 사라지기 때문이다.
그리고 수신자는 메일을 받을 때 SMTP는 Push 프로토콜이라 사용할 수 없고, Pull 프로토콜을 사용해야한다. 여기서 POP3과 IMAP 같은 메일 접속 프로토콜이 나온다.
POP3
아주 짧고 읽기 쉬운 메일 접속 프로토콜이다. 매우 단순하기 때문에 기능이 적다.
POP3은 사용자 에이전트가 메일 서버의 포트 110번으로 TCP 연결을 하면 시작한다.
인증 → 트랜잭션 → 갱신 단계로 이루어져 있다.
- 인증 단계에서는 user, pass로 이름과 비밀번호를 입력하여 인증한다.
- 트랜잭션 단계에서 다운로드, 삭제를 할 수 있다. +OK는 이전 명령을 잘 처리했다는 것이고, -ERR은 무엇인가 잘못된 것을 뜻한다.
- quit 명령을 실행하면 갱신 단계에 들어가고 메시지를 삭제한다.
POP3의 문제점은 다운로드 후 유지 모드에서는 문제 없지만, 다운로드 후 삭제 모드에서는 태블릿에서 메일을 읽었으면, 다른 기기에서는 메일을 읽을 수 없는 문제가 있다. 그리고 사용자에게 원격 폴더를 생성하거나 폴더에 메시지를 할당하는 수단이 제공되지 않는다. 그래서 IMAP이 나오게 되었다.
IMAP
IMAP은 사용자에게 원격 폴더를 생성하거나 폴더에 메시지를 할당할 수 있다.
IMAP 세션을 통해 사용자 상태 정보를 유지한다.
HTTP
웹 기반의 전자메일로 많은 사람들이 사용하고 있는 방식이다.
전자 메일 메시지는 SMTP 대신 HTTP를 사용하지만, 메일 서버간의 통신은 SMTP를 사용한다.
2. DNS
호스트를 식별하는 방법은 123.456.789.012 같은 IP 주소로 식별하는 방법과 www.google.com과 같이 호스트 네임으로 식별하는 방법이 있다.
사람의 경우 IP 주소보다 호스트 네임을 기억하기 쉬운데, 컴퓨터 입장에서는 호스트 네임으로는 얻을 수 있는 정보가 매우 적은 편이다.
그래서 호스트 네임을 IP 주소로 변환해주는 서비스가 필요한데 이것이 DNS (domain name system)의 주요 임무이다.
2.1 DNS가 제공하는 서비스
DNS는 DNS 서버들의 계층구조로 구현된 분산 데이터베이스이고, 호스트가 분산 데이터베이스로 질의하도록 허락하는 애플리케이션 계층 프로토콜이다.
만약 www.google.com/index.html를 요청한다면 호스트가 www.google.com의 IP 주소를 알고 있어야 HTTP 요청 메시지를 보낼 수 있다.
그래서 이것은 아래 단계를 수행하게 된다.
1) 사용자 컴퓨터는 DNS 애플리케이션의 클라이언트 측을 수행한다.
2) 브라우저는 URL로부터 호스트 네임(www.google.com)을 추출하고, 호스트 네임을 DNS 애플리케이션 클라이언트에 넘긴다.
3) DNS 클라이언트는 DNS 서버로 호스트 네임을 포함하는 질의를 보낸다.
4) DNS 클라이언트는 호스트 네임의 IP 주소를 얻게 된다.
5) 브라우저가 DNS로부터 IP 주소를 받으면, 브라우저는 그 IP주소와 그 주소의 80번 포트에 위치하는 HTTP 서버 프로세스로 TCP 연결을 초기화한다.
[추가 서비스]
- 호스트 엘리어싱: 호스트 네임을 여러개 가질 수 있다.
- 메일 서버 엘리어싱: 메일 서버와 웹 서버가 같은 것을 허용한다.(ex. www.naver.com과 @naver.com 같은 주소를 사용할 수 있음)
- 부하 분산: 여러 IP 주소가 같은 호스트 네임을 가질 수 있게 해서 여러 문제에 대비할 수 있도록 한다.
2.2 DNS 동작 개요
위의 추가 서비스에서 부하를 분산하는 이유는 여러가지 이유가 있다.
만약 서버가 고장나면 해당 웹은 작동하지 않는 문제도 있고, 트래픽도 혼자 감당해야하고, 서버가 한국에만 있으면 미국에서 접속을 할 때 오래 걸릴 것이다.
이것은 DNS가 분산 계층 데이터베이스인 이유도 똑같다. 웹 서버 대신 DNS 서버라고 생각하면 된다. 그래서 DNS 서버는 세 가지 유형으로 나누게 되었다.
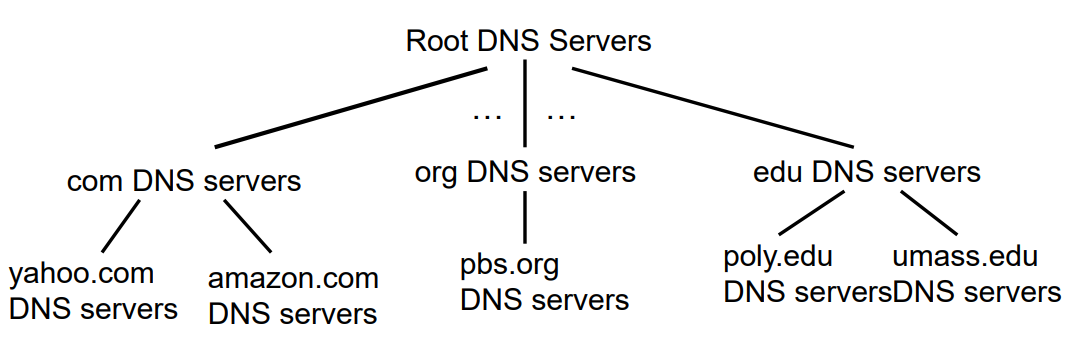
위에서부터 말하면 루트 DNS 서버, 최상위 레벨 도메인 네임(TLD) DNS 서버, 책임 DNS 서버이다.
만약 어떤 클라이언트가 www.naver.com의 IP 주소를 알고 싶다고 가정하자
1. 클라이언트는 루트 서버중 하나에 접속하고, 루트 서버는 com으로 끝나니까 com과 관련된 TLD 서버 IP 주소를 반환해준다.
2. 클라이언트는 TLD 서버중 한 곳에 접속하고, TLD 서버는 naver.com을 가지는 책임 서버의 IP 주소를 반환해준다.
3. 마지막으로 클라이언트는 책임 서버중 한 곳에 접속하여 www.naver.com의 IP 주소를 얻게 된다.
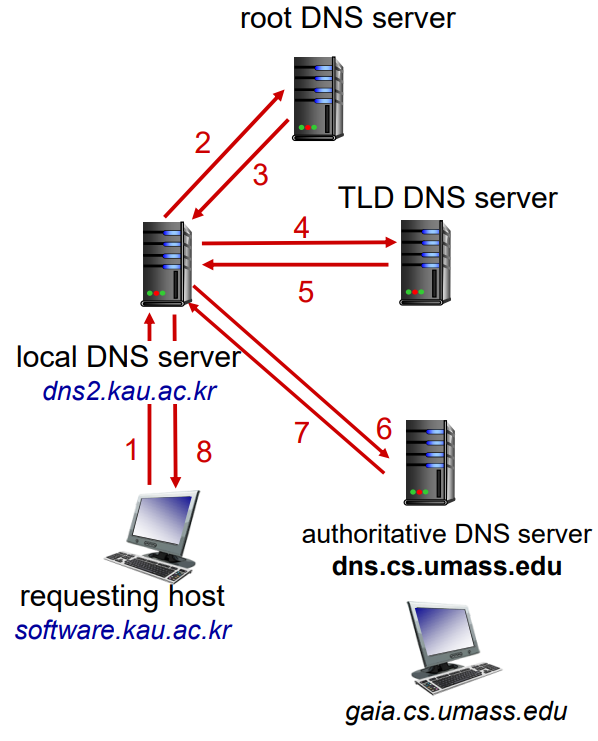
로컬 DNS 서버도 중요한데, 로컬 DNS 서버는 DNS 계층 구조에 속하지 않지만, 클라이언트 대신 로컬 DNS 서버가 위에 있던 작업을 대신 해주고 IP 주소를 클라이언트에게 반환을 해주게 된다.
이렇게 질의하는 방법을 반복적 질의라고 부르기도 한다.
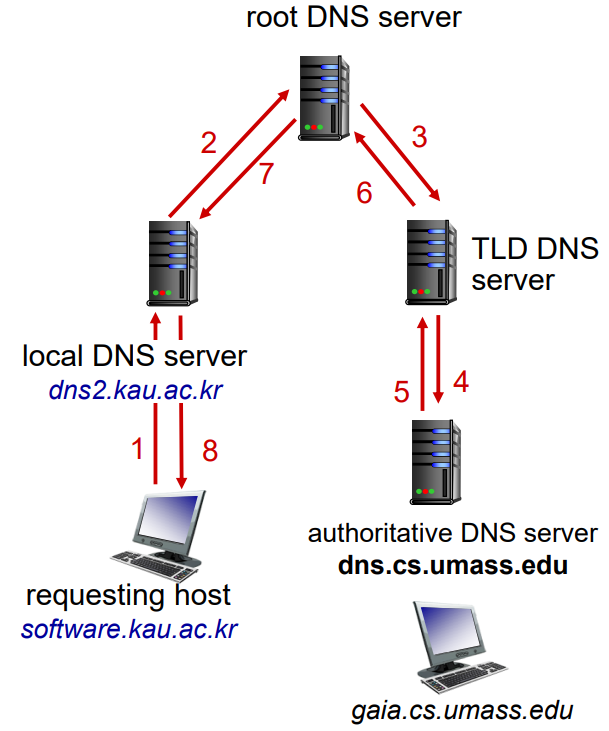
이것은 재귀적 질의라고 하는데, 재귀를 사용해야하니 반환을 하지 않은 서버는 정보를 붙들고 있어야 한다는 단점이 있다.
그래서 이것은 DNS 서버가 레코드를 가지고 있지 않을 때에만 거쳐온 서버들이 정보 저장을 할 수 있도록 사용한다.
* DNS도 빠른 응답을 해주기 위해 캐싱을 사용한다.
2.3 DNS 레코드와 메시지
[DNS 레코드]
DNS 분산 데이터베이스를 구현한 DNS 서브들은 호스트 네임을 IP 주소로 매핑하기 위한 자원 레코드(RR)를 저장한다.
자원 레코드는 (Name, Value, Type, TTL)로 4개의 튜플로 이루어져 있다.
먼저 Name과 Value는 Type에 따라 다르므로 Type부터 확인을 해야한다. TTL은 캐시에 저장되면 언제까지 가지고 있을지 결정하는 자원 레코드의 생존 기간이다.
1) Type = A : Name = 호스트 네임, Value = IP 주소
2) Type = NS : Name = 도메인, Value = 책임 DNS 서버의 호스트 네임
3) Type = CNAME : Name = 별칭 호스트 네임, Value = 원본 호스트 네임
4) Type = MX : Name = 별칭 호스트 네임, Value = Name에 대한 메일 서버의 정식 네임
[DNS 메시지]
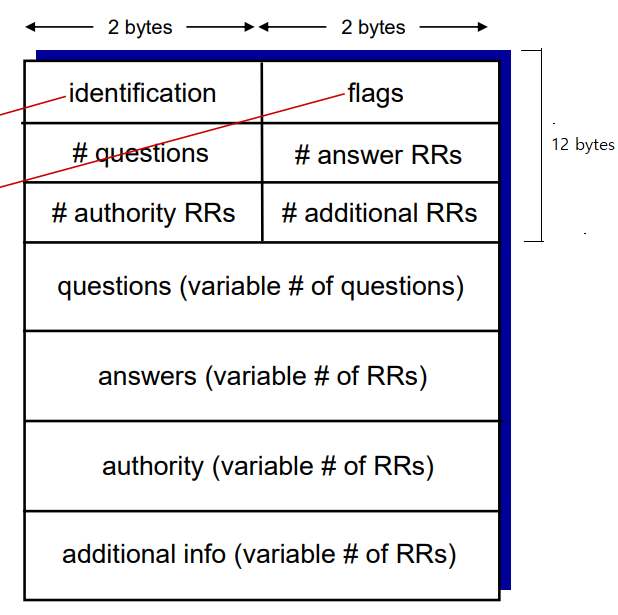
1) 헤더 영역
처음 12바이트는 헤더 영역으로 여러 필드를 가지고 있다.
- identifincation(식별자)는 나중에 응답 메시지를 보낼 때 어떤 요청 메시지랑 매칭을 해야하는지 식별할 때 사용한다.
- flags(플래그)는 메시지가 질의인지 응답인지, 현재 DNS 서버가 질의에 관한 책임 서버인지, 저장된 레코드가 없어서 재귀 질의를 해야 하는지가 있다.
- 나머지는 개수이다. 질문의 수, 답변 RR의 수, 책임 RR의 수, 추가 RR의 수가 있다.
2) 질문 영역
- question는 질문과 타입 필드(A, NS, CNAME, MX)가 있다.
- answer는 질의에 대한 응답 RR이 있다.
- authority는 책임 서버에 대한 레코드가 있다.
- additional for은 위 RR외에도 도움이 될만한 정보가 있을 경우 존재한다.
* DNS 데이터베이스에 레코드를 삽입하는 방법은 현실 세계에서 직접 등록기관에 등록을 하는 것이다.
반응형'공부 > 컴퓨터 네트워크' 카테고리의 다른 글
6. 혼잡 제어 (0) 2022.05.24 5. 파이프라인 프로토콜, TCP (0) 2022.05.24 4. 트랜스포트 계층 (0) 2022.05.23 2. 애플리케이션 계층 (0) 2022.05.17 1. 컴퓨터 네트워크와 인터넷 (2) 2022.05.10
