-
[python multiprocessing] 병렬로 데이터 처리하기학교 수업/3-1 머신러닝, 추천시스템 2022. 5. 6. 02:30반응형
추천시스템 과제를 하는데, 데이터 가공하는데 시간이 좀 오래 걸려서 멀티프로세싱을 사용하게 되었습니다.
원래 팀프로젝트 데이터 가공에 사용하려고 했는데 자꾸 Broken Pipe 에러가 나왔어서 반포기 상태였다가, 과제 데이터를 가공하는데 데이터 처리하는데 거의 20분이 걸리길래 다시 재도전하게 되었네요.
데이터는 MovieLens를 사용합니다.
다운로드는 아래 링크에서 할 수 있고, 이 글을 따라해보신다면 small data를 다운하시길 바랍니다.
https://grouplens.org/datasets/movielens/latest/
MovieLens Latest Datasets
These datasets will change over time, and are not appropriate for reporting research results. We will keep the download links stable for automated downloads. We will not archive or make available p…
grouplens.org
세부 데이터는 간단하게 movies.csv, ratings.csv만 볼 것인데,
movies.csv에서는 title, genre, movieId (영화 이름, 장르, 영화 id)을 가져오고,
ratings.csv에서는 userId, movieId, rating (유저 id, 영화 id, 평점)를 가져오려고 합니다.
위 두 데이터는 movieId로 서로 연관이 있는 데이터입니다.

제가 이 글에서 보여줄 것은 movies.csv에는 존재하는 영화지만, 아무도 평점을 매기지 않아 ratings.csv에는 존재하지 않는 영화들을 제외하기도 하고, 숫자로 0부터 k까지 연속된 숫자의 id로 만들기 위해 new_ratings.csv라는 파일을 만들어서 new_ratings.csv의 movieId를 다시 0, 1, 2, ...로 임베딩을 하려고 하는 작업을 하려고 합니다.
먼저 movies.csv와 ratings.csv를 DataFrame에 저장을 합니다.
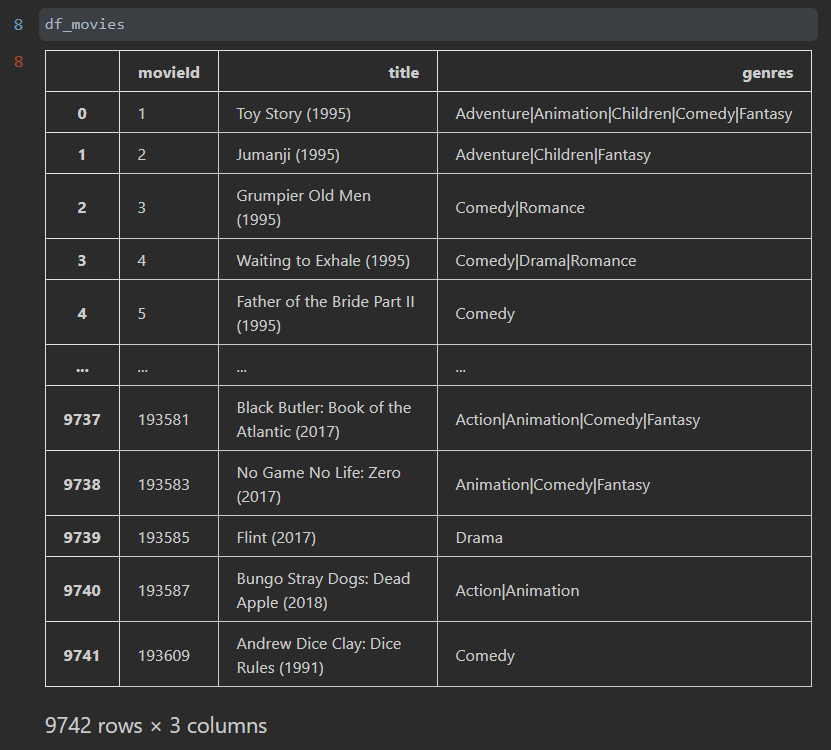
movies.csv 
ratings.csv
먼저 movies.csv와 ratings.csv에 있는 movieId의 개수가 서로 다른지 확인을 합니다.
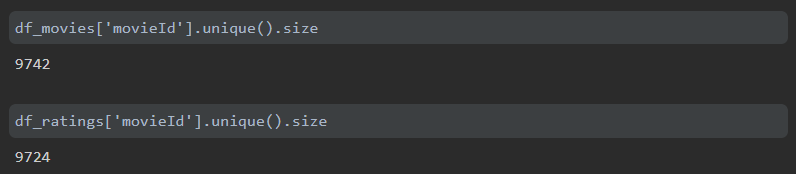
movies.csv는 영화가 9742개가 있는데, ratings.csv에는 영화가 9724개가 있습니다.
18개의 영화가 평점이 매겨져 있지 않다는 것을 알 수 있습니다. 그리고 영화가 9700여개가 있는데 movieId의 값은 193609까지 있는 것을 확인할 수 있습니다.
이제 ratings에 있는 movieId를 0부터 할당해서 임베딩하기 위해 df_remap이라는 DataFrame을 하나 만들어줍니다.

df_remap에 행을 추가하는 작업을 병렬로 처리해봅시다.
이때 서로 숫자가 겹치면 안되니까 2000개씩 나누어서 5개의 Process를 만들면 되겠네요.
5개의 프로세스에 작업을 할당하여 결과값을 저장하고, 나중에 하나로 합쳐야하니까 Manager도 필요합니다.
그래서 완성된 코드는 아래 코드입니다.
12345678910111213141516171819202122232425262728293031323334353637import pandas as pdimport multiprocessingdef worker(procnum, count, unique_movieId, df_remap, return_dict):print('start', procnum)try:for i in range(count, count + 2000):new_df_remap = pd.DataFrame({'movieId': [unique_movieId[i-count]], 'remapId': [i]})df_remap = pd.concat((df_remap, new_df_remap))return_dict[procnum] = df_remapexcept IndexError:return_dict[procnum] = df_remapprint('end', procnum)if __name__ == '__main__':df_ratings = pd.read_csv('ratings.csv', usecols=['userId', 'movieId', 'rating'])df_movies = pd.read_csv('movies.csv', usecols=['movieId', 'title', 'genres'])df_remap = pd.DataFrame({'movieId': [], 'remapId': []})unique_movieId = df_ratings['movieId'].unique().tolist()manager = multiprocessing.Manager()return_dict = manager.dict()jobs = []for i in range(5):p = multiprocessing.Process(target=worker, args=(i, i*2000, unique_movieId[2000*i:2000*(i+1)], df_remap, return_dict))jobs.append(p)p.start()for proc in jobs:proc.join()for i in range(len(return_dict.keys())):df_remap = pd.concat((df_remap, return_dict[i]))print(df_remap)cs movieId의 값 갯수가 9724개이므로 작업을 5개로 나눠 2,000개씩 일할 수 있도록 만들었습니다.
그리고 그 결과값을 return_dict에 저장하고, 작업이 다 끝나면 df_remap에 concat을 하는 방법입니다.
하지만 이 코드를 jupyter notebook에 그대로 넣으면 작동을 하지 않습니다.
작동하게 만드려면 worker 함수는 따로 파일을 만들어서 저장을 하고 import를 해야합니다.

그래서 위와 같이 코드를 다시 작성하면 제대로 데이터를 처리할 수 있게 됩니다.
이제 df_ratings에 있는 movieId의 값을 remapId의 값으로 바꾸어봅시다.
df_ratings의 행의 길이가 100,836인데 저의 cpu_count의 값은 8이니까 대충 8로 나눠서 8개의 Process를 만들어줍니다.

열심히 일하는 CPU 그리고 df_remap의 값이 float64로 되어 있으므로 new_df_ratings의 dtype은 int로 미리 선언을 해줍니다.
12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758596061626364import pandas as pdimport multiprocessingdef worker(procnum, count, unique_movieId, df_remap, return_dict):try:for i in range(count, count + 2000):new_df_remap = pd.DataFrame({'movieId': [unique_movieId[i-count]], 'remapId': [i]})df_remap = pd.concat((df_remap, new_df_remap))return_dict[procnum] = df_remapexcept IndexError:return_dict[procnum] = df_remapdef worker_ratings(procnum, df_ratings, df_remap, return_dict):for i in range(df_remap['movieId'].size):movieId, remapId = df_remap.iloc[i, :]df_ratings = df_ratings.replace({'movieId': movieId}, remapId)return_dict[procnum] = df_ratingsif __name__ == '__main__':df_ratings = pd.read_csv('ratings.csv', usecols=['userId', 'movieId', 'rating'])df_movies = pd.read_csv('movies.csv', usecols=['movieId', 'title', 'genres'])df_remap = pd.DataFrame({'movieId': [], 'remapId': []})unique_movieId = df_ratings['movieId'].unique().tolist()manager = multiprocessing.Manager()return_dict = manager.dict()jobs = []for i in range(5):p = multiprocessing.Process(target=worker, args=(i, i*2000, unique_movieId[2000*i:2000*(i+1)], df_remap, return_dict))jobs.append(p)p.start()for proc in jobs:proc.join()proc.close()for i in range(len(return_dict.keys())):df_remap = pd.concat((df_remap, return_dict[i]))new_df_ratings = pd.DataFrame({'userId': [], 'movieId': [], 'rating': []}, dtype=int)length = df_ratings['movieId'].sizereturn_dict = manager.dict()jobs = []for i in range(8):p = multiprocessing.Process(target=worker_ratings,args=(i,df_ratings.iloc[i * length // 8 : (i + 1) * length // 8],df_remap,return_dict))jobs.append(p)p.start()for proc in jobs:proc.join()proc.close()for i in range(8):new_df_ratings = pd.concat((new_df_ratings, return_dict[i]))print(new_df_ratings)cs 이것을 다시 주피터 노트북 코드에 맞게 고치면 됩니다.

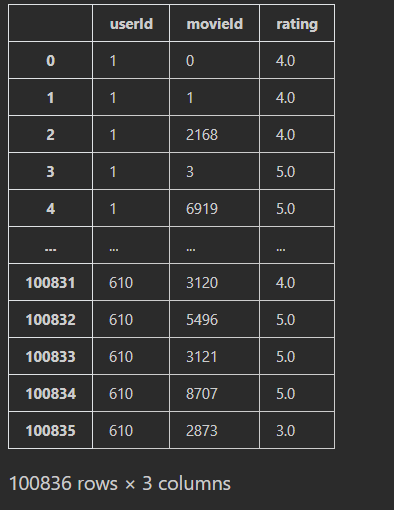
movieId의 값이 0부터 시작한다는 것을 확인할 수 있습니다.

왼쪽 = df_ratings, 오른쪽 = df_movies 좀 더 정확히 비교하기 위해 df_ratings(왼쪽)와 df_movies(오른쪽)을 가지고 왔습니다.
이 과정을 통해 간단하게 멀티프로세싱을 사용해보았습니다.
요즘 운영체제 공부를 하고 있는데, multiprocessing 모듈에 부모 프로세스랑 자식 프로세스, pid 같은 것들을 호출할 수 있어서 재밌게 했네요.
반응형'학교 수업 > 3-1 머신러닝, 추천시스템' 카테고리의 다른 글
multiprocessing Error 체크리스트 (0) 2022.05.19 Weight, Bias 초기화 (0) 2022.05.03 [GNN] Neural Graph Collaborative Filtering (NGCF) 코드 정리 (0) 2022.05.02 'float' object has no attribute 'grad' 에러 해결법 (0) 2022.04.18