-
[GNN] Neural Graph Collaborative Filtering (NGCF) 코드 정리학교 수업/3-1 머신러닝, 추천시스템 2022. 5. 2. 01:56반응형
1. 참고자료
1. 논문 리뷰
https://velog.io/@tobigs-recsys/Paper-Review-2019-ACM-Neural-Graph-Collaborative-Filtering
[Paper Review] (2019, ACM) Neural Graph Collaborative Filtering
작성자 : 이혜린 Neural Graph Collaborative Filtering (2019, ACM) 1. Introduction Recommender system은 크게 Content-based Filtering과 Collaborative Filtering으로
velog.io
https://hyez.github.io/study/paper/recommendations/ngcf/
[Paper Review] Neural Graph Collaborative Filtering
NGCF: Neural Graph Collaborative Filtering (SIGIR ‘19) 논문 리뷰입니다.
hyez.github.io
https://bladejun.tistory.com/67
Neural Graph Collaborative Filtering
2020년 3월에 발표된 Neural Graph Collborative Filtering 논문을 핵심적인 부분에 대해서만 정리해보려고한다. 궁금한점이나 틀린점이 있다면 언제나 태클 환영합니다!! 해당 그림은 user-item 상호작용 그
bladejun.tistory.com
2. 깃허브 코드
https://github.com/huangtinglin/NGCF-PyTorch
GitHub - huangtinglin/NGCF-PyTorch: PyTorch Implementation for Neural Graph Collaborative Filtering
PyTorch Implementation for Neural Graph Collaborative Filtering - GitHub - huangtinglin/NGCF-PyTorch: PyTorch Implementation for Neural Graph Collaborative Filtering
github.com
2. 코드 분석
팀플에 쓸 모델인데, 나는 노베이스라고 보면 되는 수준이라 논문에 있던 내용과 실제 코드에서 어떻게 적용되고, 어떻게 돌아가는지 알아보고자 정리를 하게 되었다. 댓글로 물어봐도 아는게 없어서 대답 못 함
여기서 언급되는 데이터는 gowalla 데이터를 사용한다.
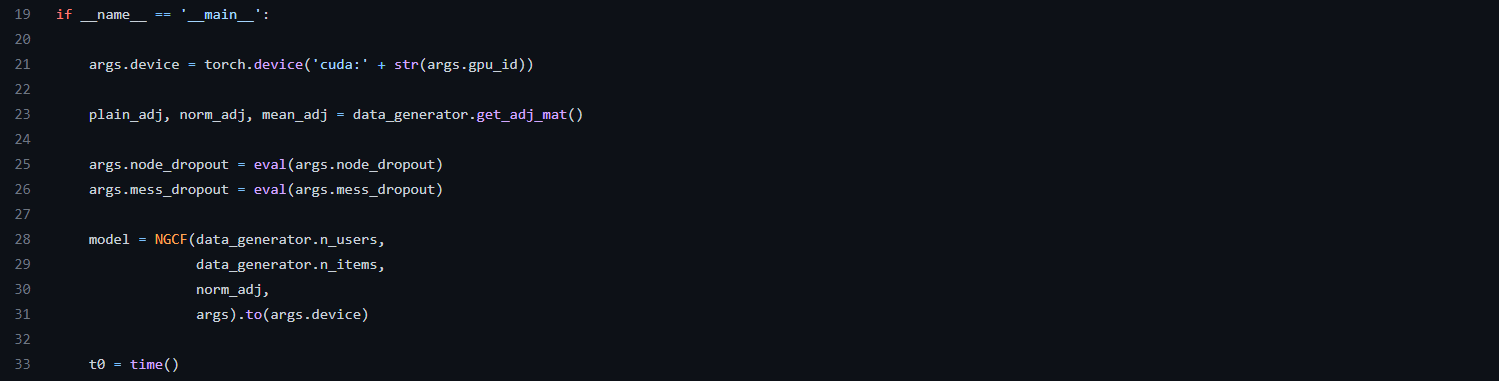
[main] line 21
args.device는 학습을 할 때, 특정 gpu_id를 가진 gpu를 사용하여 학습시키는 것이다.
[main] line 23
data_generator는 Data 객체를 생성하고, get_adj_mat()은 Data 폴더에 있는 인접리스트의 데이터를 받아 scipy.sparse.load_npz를 통해 3개의 matrix를 만든다.
이때 matrix는 크기가 (user 수 + item 수, user 수 + item 수)인 희소 행렬이며, 예를 들어 gowalla 데이터를 사용할 경우에는 유저의 수는 29858이고, 아이템의 수는 40981라서 29858 + 40981 = 70839로 (70839, 70839)인 행렬이 나온다.
plain_adj
행렬 값은 plain_adj[0][29858] = 1 로 plain_adj[유저id][아이템id] = 1 혹은 plain_adj[아이템id][유저id] = 1로 표현된 행렬이다.
ex) user_id = 1에 연결된 item_id가 1, 2, 3이면 index는 0부터 시작하니까 user_id의 값을 0으로 바꿔서 plain_adj[0][1] = 1, plain_adj[0][2] = 1, plain_adj[0][3] = 1이 나오게 된다.
norm_adj
이 값은 인접리스트로 연결된 값들의 평균값이 나온다.
아래에서 1을 더해주는 것은 자기 자신의 값까지 포함하는 것이다.
norm_adj[user_id][item_id]의 경우에는 어떤 유저가 여러개의 아이템을 가지고 있는데, 1에다가 (아이템의 개수 + 1)만큼 나눠서 할당하는 것이다.
norm_adj[item_id][user_id]의 경우에는 어떤 아이템이 여러 명의 유저와 연결되어 있는데, 1에다가 (유저의 수 + 1)만큼 나눠서 값을 할당해준다.
ex) user_id = 1에 연결된 item_id가 1, 2, 3이면 norm_adj[0][0] = 0.25, norm_adj[0][1] = 0.25, norm_adj[0][2] = 0.25, norm_adj[0][3] = 0.25가 나온다.
mean_adj
norm_adj에서 자기 자신을 제외한 평균값을 구한다. (순수한 평균값을 구해서 할당해준다.)
mean_adj[user_id][item_id]의 경우에는 어떤 유저가 여러개의 아이템을 가지고 있는데, 1에다가 (아이템의 개수)만큼 나눠서 할당하는 것이다.
mean_adj[item_id][user_id]의 경우에는 어떤 아이템이 여러 명의 유저와 연결되어 있는데, 1에다가 (유저의 수)만큼 나눠서 값을 할당해준다.
ex) user_id = 1에 연결된 item_id가 1, 2, 3이면 norm_adj[0][1] = 0.333.., norm_adj[0][2] = 0.333.., norm_adj[0][3] = 0.333..이 나온다.
[main] line 24 ~ 25
node_dropout = [0.1], mess_dropout = [0.1, 0.1, 0.1]로 설정해준다.
dropout될 확률을 설정해주는 것 같다.
[main] line 28 ~ 31
NGCF 객체를 만든다.이때 들어가는 파라미터는 4개인데data_generator.n_users는 유저의 수,data_generator.n_items는 아이템의 수,norm_adj는 위에서 언급한 행렬,args는 이 파일을 실행할 때 설정한 세팅이다.
이렇게 세팅하였으면 이제 시간을 측정하고 학습을 시작한다.
이제 아래 velog의 Methodology를 참고해야 한다.
[Paper Review] (2019, ACM) Neural Graph Collaborative Filtering
작성자 : 이혜린 Neural Graph Collaborative Filtering (2019, ACM) 1. Introduction Recommender system은 크게 Content-based Filtering과 Collaborative Filtering으로
velog.io
여기서 옵티마이저는 Adam을 사용한다.
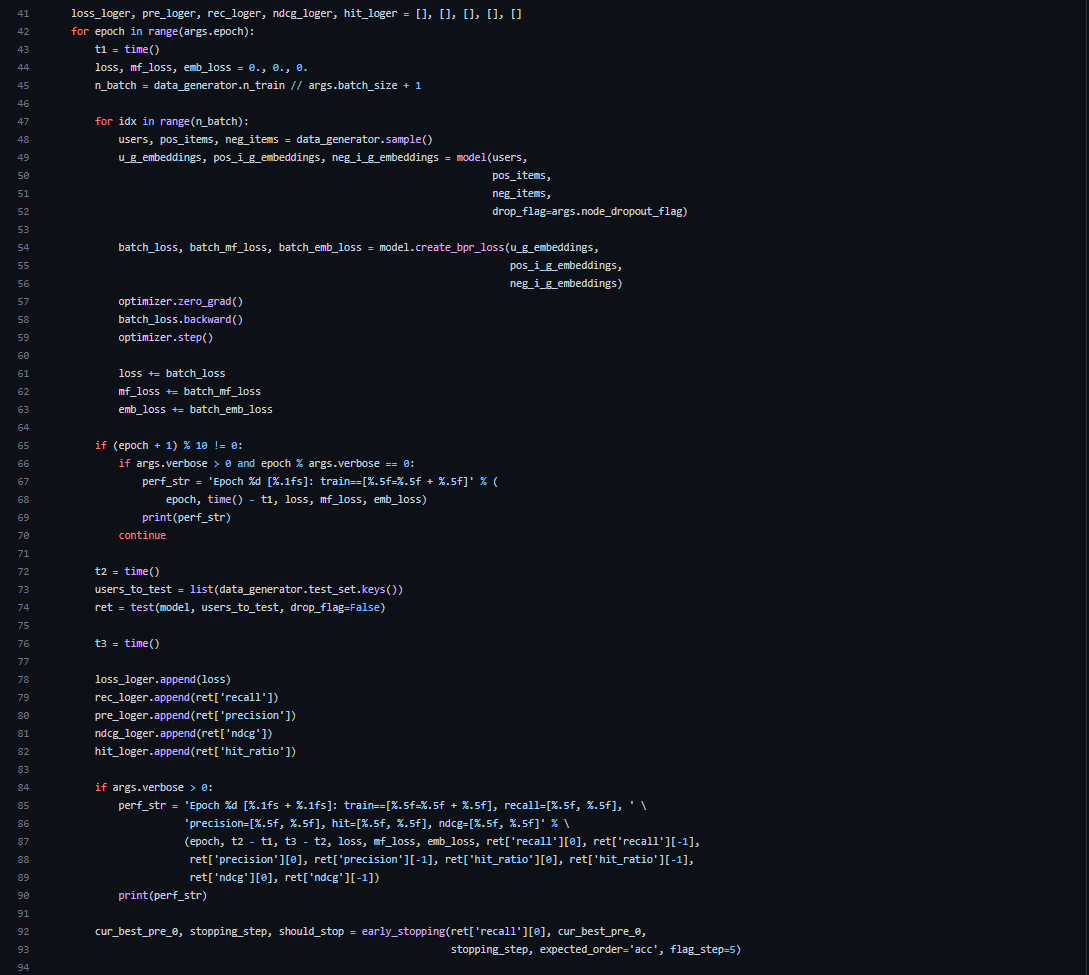
main.py [main] line 45
n_train = 810128, batch_size = 1024 → n_batch = 792
[main] line 48
학습을 한다. 먼저 line 48의 data_generator.sample()에 대해 알아보자
sample에 대한 코드는 utility.load_data.py에 있다.
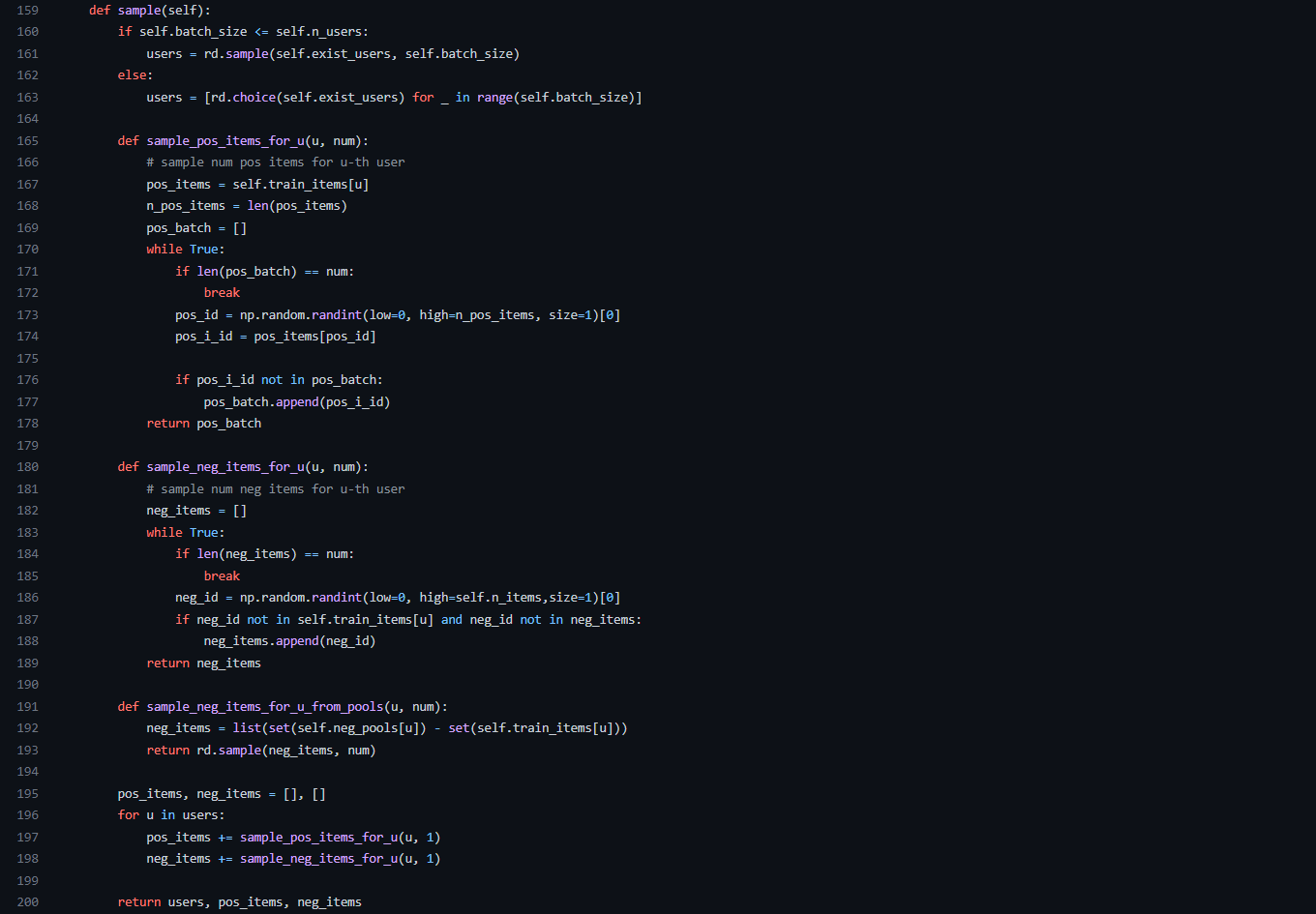
load_data.py [load_data - sample] line 160 ~ 163
exist_users는 user_id를 저장한 리스트이다.
users라는 변수에 배치 사이즈만큼 exist_users에서 랜덤하게 가져온다.
[load_data - sample] - line 165 ~ 178 (sample_pos_items_for_u)
train_items는 딕셔너리로 key는 user_id, value는 user_id와 연결된 item_id를 가지고 있다.
Data에서 train.txt에 있는 인접리스트를 딕셔너리로 변환한 것이다.pos_items = train_items[u] → user가 가지고 있는 item들while문 안에서는 이 아이템중에 1개를 랜덤하게 뽑아서 pos_batch에 1개를 저장하고 return한다.즉, 반환하는 pos_batch는 user_id와 연결된 item_id중 한 개를 가져온 것이다.
[load_data - sample] - line 180 ~ 189 (sample_neg_items_for_u)
neg_id 값은 전체 item_id중에 랜덤한 값 1개를 저장한다.그리고 neg_id 값이 user_id의 train_items에 속하지 않는 값이라면 neg_items라는 리스트에 저장하여 return한다.즉, 반환하는 neg_items는 user_id의 train_items에 속하지 않는 랜덤한 item_id이다.
[load_data - sample] - line 195 ~ 200
이제 우리가 위에서 구한 users의 수(배치 사이즈)만큼 반복문을 돌려서 pos_batch와 neg_items값을 가져와서 각각 pos_items와 neg_items에 저장하여 반환해준다.
[main] line 48
sample에서 반환한 users, pos_items, neg_items가 변수명까지 그대로 넘어오게 된다.
main.py [main] line 49 ~ 52
이 코드를 이해하려면 NGCF의 forward를 확인해야한다.

NGCF.py [NGCF - forward] line 105 ~ 107
A_hat은 NGCF - sparse_dropout의 코드를 봐야 알 수 있다.

NGCF.py [NGCF - sparse_dropout] line 71 ~ 82
random_tensor는 noise_shape(= sparse_norm_adj._nnz)의 크기이며 [0, 1) 값을 가지는 텐서를 만들어서 0.9(= 1-rate)를 더해준다. 여기서 sparse_norm_adj.nnz는 norm_adj를 희소행렬 표현방식중 하나인 coo 희소 표현을 사용한 것인데, 0이 아닌 값들의 개수이다. 단순히 norm_adj에서 0이 아닌 값들의 개수라고 생각하면 될 것 같다.
이후 dropout을 적용하기 위해 random_tensor를 bool 타입으로 변환하여 저장하는데, 0.9를 더해주므로 대부분의 값이 True로 변한다. False인 비율은 대략 10%가 나온다.
i는 행이 2인 matrix로 되어 있는데, 이전에 우리가 norm_adj를 저장할 때 user_id와 (user_id + item_id)로 저장을 하였다. 그래서 첫번째 행은 user_id로 이루어진 리스트이고, 두번째 행은 user_id와 item_id로 이루어져있다. 이것은 일대일로 연결되어 있다.
예를 들어서 user_id = 1, item_id = [2, 3], user_id = 3, item_id = [10, 11]이라면 i = [[1, 1, 3, 3], [2, 3, 10, 11]]이다.
v는 norm_adj에 있는 0이 아닌 값들을 다 모아서 벡터로 변환한 값이다.
그래서 i와 v로 표현되었고, 크기가 norm_adj와 같은 (user + item, user + item)인 sparse matrix를 반환한다.
드디어 A_hat가 무엇인지 알 수 있었다.
간단히 요약하면 A_hat은 dropout에서 살아남은 위치값과 해당 위치의 값을 뜻한다.
NGCF.py [NGCF - forward] line 109 ~ 110
드디어 velog에 나오는 내용이 나온다.

ego_embeddings가 위 수식을 뜻한다. 임베딩 크기는 64이다.
이 값은 embedding_dict['user_emb'], embedding_dict['item_emb']을 concat한 값을 가지고 있는데, 딕셔너리 각각의 값은 행이 유저/아이템의 크기이고, 열의 개수는 임베딩 크기인 64이다. 값은 empty로 초기화한 값이다.
gowalla의 유저 수는 40981명, 아이템 수는 29858개이니까 ego_embeddings의 행의 수는 70839이다.
코드를 살펴보기전에..
이제 Embedding Propagation Layers를 구현해야 한다.
논문에서는 First-order Propagation과 High-order Propagation으로 나누어져서 진행되고 있다.
- First-order Propagation
1) Message Construction
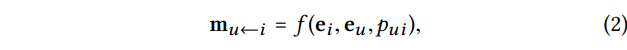
이것은 데이터에서 (user, item) pair를 만든다. 이때 pui는 decay factor로 매 전파마다 메시지의 값이 약하게 전달되는 것을 방지해준다고 한다.
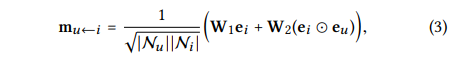
함수 f에 대한 자세한 내용은 위 식으로 볼 수 있다.
이것은 user와 item 간의 상호작용을 메시지에 인코딩한다는 것이다. 위 식은 유사한 아이템에 대해 더 많은 메시지를 전달할 수 있다고 한다.
여기서 1 / sqrt(|Nu||Ni|) 는 Graph Laplacian Norm으로 정규화된 라플라시안 행렬 값이라고 한다. 라플라시안 행렬 값은 무엇이냐면 (차수 행렬) - (인접 행렬)을 계산하면 된다고 한다. 이걸 쓰는 이유는 검색해보니까 많은 정보가 한 행렬로 표현 가능해서 그렇고, 여기서는 과거의 데이터가 유저에게 얼마나 반영될지 결정하는 값이라고 한다. (구글링을 해봐도 정확한 뜻이 무엇인지 모르겠다.)
어쨌든 저런 방식을 사용해서 값을 구한다.

2) Message Aggregation (메시지 집계)
이것은 u의 이웃노드들로부터 전파된 메시지를 집계하는 단계이다.
u의 이웃노드들로부터 전파된 메시지와 u 자신에게 보내는 메시지까지 합쳐서 활성화 함수(LeackyReLU)를 적용한다.
이것을 통해 만들어진 값 eu(1)이 u에 대한 첫번째 임베딩 레이어의 표현이라고 한다.
그럼 이제 High-order propagation에 대해 알아보자
- High-order propagation
이런 embedding propagation layer를 쌓아두면 high-order connectivity 정보를 얻을 수 있다.
여기서 l개의 layer를 쌓으면 l-hop neighbors로부터 집계된 메시지를 받을 수 있다는 것이다.
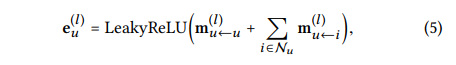
l층의 값은 위 식으로 구할 수 있는데 message 값을 아래 식으로 구해야 한다.

이런 짓을 왜하냐면 아래 그림을 보자

만약 3-hop이라고 가정하고, ei4(0) → eu2(1) → ei2(2) → ee1(2) 순서로 빨간 동그라미가 되어 있는 것을 알 수 있다. 이것은 item i[4]가 user u[1]의 임베딩 벡터에 정보가 표현되어 있음을 알 수 있다. (collaborative signal)
이제 마지막으로 Propagation Rule in Matrix Form을 보자 이것은 Embedding Propagation의 규칙을 말하는 것 같다.
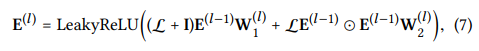
여기서 L인 라플라시안 행렬은 아래 식과 같다.

이런 방법을 사용한다면 representation update를 일괄적으로 적용하여 더 효율적으로 학습을 할 수 있다고 한다.
이렇게 해서 학습에 필요한 전파 과정은 끝났고, 이제 예측을 하기 위한 과정으로 넘어간다.
3) Model Prediction
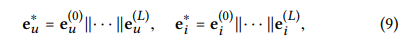
L 개의 embedding propagation layer를 거쳐서 나온 결과물은 모든 층에 대한 user에 대한 값 {eu(1), ..., eu(L)}과 item의 값 {ei(1), ..., eu(L)}을 얻을 수 있다.
여기서 위 식대로 각각의 임베딩 층을 concat하여 final embedding을 얻는다.

이후 단순 내적을 통해 NGCF의 값을 구한다. 단순 내적 대신 다른 함수를 사용하는 것을 미래의 연구 방향성으로 남겨두었다고 한다.
4) 다른 내용
- Loss는 BPR Loss를 사용 (유저가 사용한 아이템에 대해 많이 반영한다.)
아래 식에서 y_hat_ui는 긍정적인 item, y_hat_uj는 부정적인 item이다.

- Optimizate는 Adam을 사용 (국룰)
- Message and Node Dropout (overfitting 때문에)
이렇게 해서 얼추 NGCF에 대한 논문 내용이 끝나게 된다.
NGCF.py [NGCF - forward] line 115
먼저 side_embedding은 A-hat과 ego_embedding을 곱하는데, 이것은 dropout을 적용시킨 것이다.
[NGCF - forward] line 115 ~ 137
위 논문에서 말한 first-order ~ high-order를 뜻한다
[NGCF - forward] line 139 ~ 141
원래 임베딩 값이 층 별로 나누어져 있는데, 이것을 {유저, 아이템} 하나로 묶고 user, item으로 나누어준다. 이 값은 3) Model Prediction과 같다.
이후 loss에 사용할 수 있게 user 임베딩, 긍정적인 item 임베딩, 부정적인 item 임베딩으로 나눠 반환한다.
이제 다시 main.py로 돌아온다.

[main] line 49 ~ 52
우리가 위에서 배웠던 훈련이다.
[main] line 54 ~ 63
BPR loss를 구하는 것이다. NGCF.py에 보면 코드가 있는데, 논문에 나온 식을 거의 그대로 사용한다.
[main] 이후 내용
10번의 epoch마다 테스트를 하여 loss 값을 알려준다.
이때 마지막줄에 early_stopping이라는 기법을 사용하는데, 과적합을 피하기 위해 조기종료를 하는 것인데 이러면 성능이 더 좋아진다고 한다.
반응형'학교 수업 > 3-1 머신러닝, 추천시스템' 카테고리의 다른 글
multiprocessing Error 체크리스트 (0) 2022.05.19 [python multiprocessing] 병렬로 데이터 처리하기 (0) 2022.05.06 Weight, Bias 초기화 (0) 2022.05.03 'float' object has no attribute 'grad' 에러 해결법 (0) 2022.04.18