-
6. 혼잡 제어공부/컴퓨터 네트워크 2022. 5. 24. 21:54반응형

이 글은 Computer Networking: A Top-Down Approach 7th를 읽고 정리한 글입니다.
1. 혼잡제어의 원리
흐름제어와 혼잡제어의 공통점은 송신자가 너무 많은 데이터를 보내는 것에서 출발하기 시작한다는 것이고,
흐름제어와 혼잡제어의 차이점은 흐름제어는 송신자-수신자의 관계, 혼잡제어는 송신자-네트워크의 관계에 대한 것이다.
우리는 1장에서 라우터가 패킷을 처리하기 전에 큐에 들어간다는 것을 배운적이 있었다. 그런데 라우터는 한 번에 하나의 패킷만 처리할 수 있어서 많은 수의 패킷이 들어오게 되면 아직 처리를 못한 패킷은 큐에 저장을 한다. 이때 큐의 용량이 꽉차게 되면 패킷 손실이 일어난다는 배웠다.
그래서 혼잡제어란 이런 네트워크의 처리 속도가 송신자의 전송 속도를 따라잡을 수 없어서 패킷 손실이 일어날 수 있기에 송신자의 전송 속도를 강제로 느리게하는 기능을 말한다.
1.1 혼잡의 원인과 비용
혼잡제어가 일어나는 세 가지 시나리오를 확인해보자
[시나리오 1] 2개의 송신자와 무한 버퍼를 갖는 하나의 라우터
이 경우에는 라우터의 버퍼 용량이 무한으로 패킷 손실이 전혀 일어나지 않는 상황이다.
그래서 패킷을 보내면 언젠가는 다 전송을 하게 된다.
이 시나리오에서는 호스트 A와 호스트 B가 같은 λin byte/sec으로 보내고 있는 이상적인 환경이라고 가정하고, 마찬가지로 라우터의 패킷 처리 속도는 λin byte/sec라고 하자
그러면 호스트 A, 호스트 B와 라우터가 연결된 링크들은 라우터에 50:50 비율로 패킷을 전달할 것이다.
라우터가 링크에게 받을 수 있는 용량을 R이라고 하면 각 링크들은 R/2씩 라우터에 보내는 것이다.
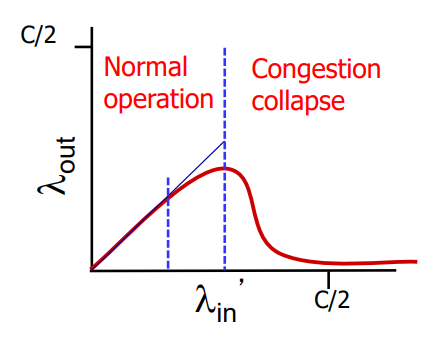
이제 왼쪽 그래프를 살펴보면 호스트에서 아무리 많은 패킷을 보내봤자 라우터의 패킷 처리는 R로 제한되어 있으므로 여기서는 호스트 A, 호스트 B 두명이 패킷을 보내니까 한 명의 호스트는 최대 R/2의 패킷을 처리 받을 수 있는 것이다.
오른쪽 그래프를 살펴보기전에 패킷은 일정하게 들어오는 것이 아니라 평균이 이라는 것이지, 실제로는 랜덤한 수로 패킷이 전달되는편이다. 그리고 우리는 이전에 라우터는 한 번에 하나의 패킷만을 처리하고 있다는 것을 배웠었다.
그래서 오른쪽 그래프는 라우터의 처리 속도는 정해져 있는데, 패킷이 한 번에 몰려서 들어오게 되면 버퍼에 패킷이 적재되고, 이런 과정으로인해 λin의 값이 R/2로 갈수록 쌓이는 데이터의 양이 많아지기 때문에 지연시간이 R/2로 가면 영원히 패킷을 받지 못하는 무한대로 수렴하게 된다.
[시나리오 2] 2개의 송신자, 유한 버퍼를 가진 하나의 라우터
시나리오 1과 다르게 라우터의 버퍼 용량이 유한하다고 가정하는 시나리오이다.
이러면 버퍼가 가득찼는데 버퍼에 들어오려는 패킷은 버려지게 되고, 호스트는 다시 패킷을 재전송하게 된다.
여기서 원래 데이터만을 소켓으로 보내는 송신율을 λin byte/sec라고 하고, 원래 데이터와 재전송 데이터를 포함하는 송신율을 λ'in byte/sec라고 한다.
이때 패킷을 하나 복사하는데 재전송을 하려면 패킷이 있어야하니까 복사를 한다. 그리고 이 복사된 패킷은 무조건 라우터 버퍼가 비어있을때 보낸다고 가정한다.
[상황 1] 버퍼가 비어있을 때만 데이터를 전송한다는 상황
버퍼가 비어있을 때에만 데이터를 전송하니 그래프의 처리량은 시나리오 1과 같게 된다.
[상황 2] 패킷이 손실된 것을 알았을 때, 재전송하는 경우

여기서는 데이터에 원래 보내는 데이터와 재전송해야하는 데이터가 있어서 R/2로 보내면 원래 데이터의 성능이 낮게 나온다. 하지만 재전송을 보내는 패킷은 우리가 버퍼가 비었을 때를 가정해서 보내기 때문에 데이터양이 늘리면 R/2로 수렴을 하게 된다.
[상황 3] 송신자에서 너무 일찍 타임아웃이 되어 패킷이 손실되지 않았지만 다시 보내는 경우

여기서는 단순 재전송을 하는 것과 비슷하지만, 수신측에서 중복된 패킷을 버려야하는 처리량도 존재하기 때문에 결코 R/2로 수렴할 수 없다.
[시나리오 3] 4개의 송신자와 유한 버퍼를 가지는 라우터, 그리고 멀티홉 경로

여기서는 호스트가 2-홉(라우터를 2개 통과한다는 뜻) 경로를 통해 패킷을 전송한다.
위 사진에서 맨 오른쪽에 있는 라우터의 경우에는 패킷이 호스트 A → 호스트 C가는 경로(빨강)에도 거치게 되고, 호스트 B → 호스트 D로 가는 경로(초록)에도 거치게 된다.이때 만약 호스트 A → 호스트 C로 가는 패킷이 유실이 되어 재전송을 하게 된다면 호스트 A → 호스트 C의 성능에 영향을 받는 것뿐만 아니라 호스트 B → 호스트 D의 성능에도 영향을 받는다.
이 그래프는 호스트 A → 호스트 C로 가는 패킷이 잘 가고 있다가 어느 순간부터는 패킷이 쌓이게 되는 경우를 말한다. 이러면 호스트 A → 호스트 C로 가는데 재전송으로 패킷이 쌓이게되어 호스트 B → 호스트 D로 잘 가고 있던 패킷보다 기하급수적으로 많아지는 경우, 패킷들도 경쟁을 하기 때문에 버퍼가 호스트 A → 호스트 C의 패킷으로 채워지게 된다. 그러면 잘 가고 있던 호스트 B → 호스트 D의 처리량이 0에 가까워지게 된다는 것이다.
거기다가 중복된 데이터가 들어오면 중복된 패킷을 버리는 것도 고려를 해야하기 때문에 성능이 더 안좋게 나온다.
1.2 혼잡제어에 대한 접근법
1) 종단간의 혼잡제어
종단간의 접근법에서는 네트워크 계층이 혼잡제어를 위해 아무런 지원을 직접적으로 해주지 않는다.
IP 계층이 어떠한 피드백을 제공하지 않으므로 TCP가 혼잡제어를 위한 종단간의 접근을 수행해야한다.
자세한 내용은 바로 밑에 나오는 TCP 혼잡제어에서 자세히 배우게 된다.
2) 네트워크 지원 혼잡제어
여기서는 네트워크 계층이 네트워크 안에서 혼잡 상태와 관련하여 송신자에게 직접적인 피드백을 제공한다.
피드백 방법 1) 라우터가 송신자에게 패킷을 전달해서 지금 혼잡하다고 알린다.
피드백 방법 2) 송신자에서 수신자로 보내는 패킷의 특정 필드에 혼잡하다는 내용을 넣는다. 그러면 수신자가 확인하고 송신자에게 전송하게 된다.
2. TCP 혼잡제어
위에서 언급했듯이 종단간의 혼잡제어는 네트워크 계층이 전혀 피드백을 하지 않는다. 그래서 TCP가 혼잡제어를 해야한다.

혼잡 제어를 소개하기 전에 알아야할 내용은 TCP 송신자가 전송률을 제한하는 방법은 혼잡 윈도우(cwnd)를 사용하는 것이다.
cwnd는 네트워크로 트래픽을 전송할 수 있는 비율을 제한하며, 송신하는 쪽에서 확인응답이 안 된 데이터의 양은 cwnd와 rwnd(이전 절에 나온 버퍼의 남은 용량)의 최솟값을 초과하지 않는다.
LastByteSent - LastByteAcked ≤ min(cwnd, rwnd)
그래서 버퍼 용량이 무한하다고 해도 확인응답이 아직 되지 않은 데이터의 양은 오로지 cwnd만큼만 생기게 된다.
2.1 AIMD (Additive Increase Multiplicative Decrease)

* RTT: 패킷이 목적지에 도달하고, 수신자가 송신자에게 받았다고 확인 패킷을 보내는 시간 (패킷 왕복 시간)
* MSS: 최대 바이트 수
TCP 송신자가 경로에 혼잡이 없으면 매번 RTT당 cwnd의 크기를 1MSS씩 높이고(additive increase), 송신률을 서서히 높이다가 나중에 혼잡이 존재하게 되면 cwnd의 크기를 반절로 줄이고 다시 RTT당 1MSS씩 올린다.(multiplicative decrease)
2.2 Slow Start

혼잡이 있을 경우 cwnd의 크기를 1로 줄이고, 혼잡이 없을 때마다 cwnd의 크기를 두배씩 늘린다.
그러다가 cwnd의 크기가 ssthresh(slow start sthreshold)라는 임계치와 같아지게 되면 slow start 방식은 종료되고 혼잡 회피 모드로 들어간다.
혼잡 회피 모드는 혼잡 상태가 되면 slow start처럼 2배를 증가시키는 것이 아니라 조금씩 증가시킨다. 그리고 3번의 중복 ACK들이 검출되면 TCP는 빠른 재전송을 수행하여 빠른 회복 상태로 들어간다.
2.3 혼잡 회피

혼잡 회피 상태가 되는 시점에서 cwnd의 값은 대략 혼잡이 마지막 발견된 시점에서의 값의 반이 된다. (ssthreash 값이 그렇다)
혼잡 회피 상태동안 혼잡 상태가 일어나지 않는다면 RTT당 1MSS만큼 증가를 하게 된다.
하지만 여기서도 slow start와 똑같이 혼잡 상태가 되면 cwnd값을 1로 설정하고, 추가로 ssthreash값을 혼잡 상태가 일어난 cwnd값의 반절로 설정을 하고 다시 slow start로 시작한다.
여기서 매번 1로 다시 시작하는 것은 굉장히 비효율적이기 때문에 혼잡 회피 상태에서 혼잡 상태가 일어나면 빠른 회복 상태로 들어가게 된다.
2.4 빠른 회복

여기서 cwnd의 크기가 12일 때 혼잡 상태가 일어나게 되고, 재전송을 하게되므로 3개의 중복 ACK이 나오거나 timeout이 일어나게 된다.
그러면 cwnd의 값을 cwnd/2로 변경하고 중복 ACK이 나온 수만큼 더해준다. 그러면 12 → 9(12/2 + 3)이 되는 것이다.
이후에도 중복된 ACK이 나온 수만큼 더해주어서 12 → 9 → 12가 된다. 이후엔 cwnd/2로 변경해서 다시 1씩 올린다.
과정이 좀 복잡하긴한데, 왜 12 → 9 → 12 → 6이 되냐면 데이터를 빨리 전송해야하기 때문에 12 → 6보다는 잠깐이라도 더 많이 보낼 수 있기 때문이라고 한다.
2.5 요약

처음에는 slow start로 시작했다가 ssthreash를 넘기면 혼잡 회피 상태가 되고, 혼잡 상태가 일어나면 빠른 회복을 도모한다.
2. 공평성

궁극적으로 이런 혼잡 제어를 하는 이유가 뭐냐면 패킷을 공평하게 보내야하기 때문이다.

공평해지는 과정을 예시를 통해 알아보자 (그림은 아래 내용을 봐야 이해할 수 있다.)
라우터의 버퍼 용량이 16일 때, Host-1의 패킷과 Host-2의 패킷 수의 개수를 나타낸 것이다.
1) Host-1: 10, Host-2: 2
2) Host-1: 11, Host-2: 3
3) Host-1: 12, Host-2: 4
4) Host-1: 6, Host-2: 2 (반절씩 줄임)
5) Host-1: 7, Host-2: 3
6) Host-1: 8, Host-2: 4
7) ~ 9): Host-1: 10, Host-2: 6
10) Host-1: 5, Host-2: 3 (반절씩 줄임)
...
이렇게 되면 결국엔 패킷을 공평하게 보낼 수 있게 된다는 것을 보여준다.
반응형'공부 > 컴퓨터 네트워크' 카테고리의 다른 글
8. NAT, IPv6, ICMP, Routing Algorithm (0) 2022.05.30 7. 네트워크 계층 (0) 2022.05.27 5. 파이프라인 프로토콜, TCP (0) 2022.05.24 4. 트랜스포트 계층 (0) 2022.05.23 3. e-mail, DNS (0) 2022.05.18
