-
[빅데이터의 탐색] 2. 열 지향 스토리지에 의한 고속화책/빅데이터를 지탱하는 기술 2022. 3. 23. 15:28반응형

이 글은 빅데이터를 지탱하는 기술을 읽고 정리한 글입니다.
1. 데이터베이스의 지연 줄이기
데이터 양이 많아지면 집계하는데 오랜 시간이 걸릴 수도 있기 때문에 데이터를 오래 집계하는 것을 예상해서 시스템을 구축해야 한다. 그래서 데이터 집계에서는 빠르면 빠를수록 좋지만, 크로스 집계가 항상 초 단위로 응답할 수 있게 크로스 집계를 중심으로 구축을 해야 한다.
- 데이터 처리의 지연
데이터 처리의 응답이 빠르다 = 대기 시간이 적다 = 지연이 적다
데이터 마트를 만들 때는 지연이 적은 데이터베이스가 있어야 하는데, 가장 간단한 방법은 모든 데이터를 메모리에 올리는 것이다. 메모리에 모든 데이터를 올릴 수 있는 경우 데이터 마트는 RDB를 사용하는 것이 적합한데, 단점은 메모리 용량이 부족할 경우 성능이 급격하게 나빠진다는 점이다. 거기다가 수억 레코드를 초과하는 데이터 집계에서는 항상 디바이스 I/O가 발생한다고 생각하면 된다.
- 압축과 분산에 의해 지연 줄이기
고속화를 위해 사용되는 기법이 데이터를 가능한 작게 압축하고, 여러 디스크에 분산 저장하여 데이터 로드에 따른 지연을 줄이는 것이다. 이때 MPP(Massive Parallel Processing) 아키텍처를 사용하면 분산된 데이터를 멀티 코어를 활용하면서 디스크 I/O를 병렬 처리할 수 있어서 데이터 집계에 최적화되어 있다.
2. 열 지향 데이터베이스 접근
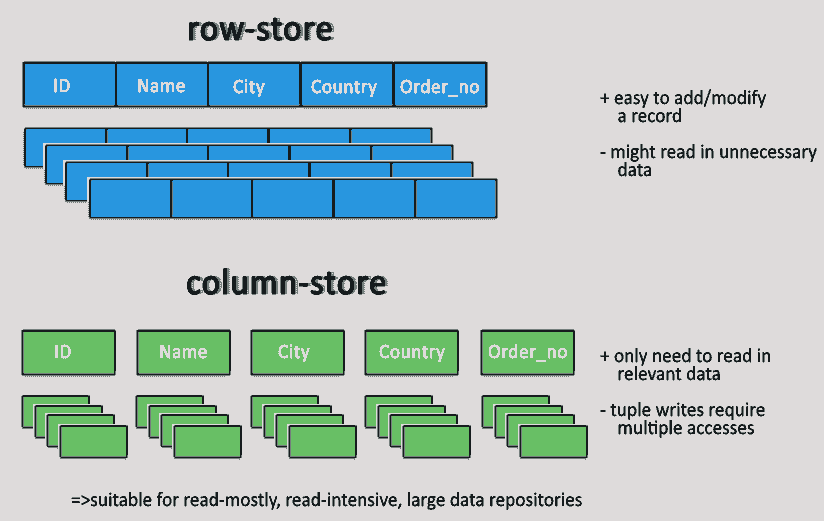
https://mkhernandez.wordpress.com/2019/01/19/column-oriented-nosql-databases/ - 행 / 열 지향 데이터베이스 소개
일반적으로 데이터베이스는 행 단위로 데이터를 읽거나 쓰고 있는데, 이것을 행 지향 데이터베이스라고 부른다. 대표적으로 한 번쯤은 접해봤을 MySQL이나 Oracle DB가 있다. 하지만 데이터 분석에 사용되는 데이터베이스는 칼럼 단위의 집계에 최적화가 되어 있으며 이것을 열 지향 데이터베이스라고 부르고 대표적으로 Teradata와 Amazon Redshint가 대표적인 열 지향 데이터베이스이다.
- 행 지향 데이터베이스
행 지향 데이터베이스는 새 레코드를 추가할 때, 파일의 데이터만 작성하면 되서 빠르고 효율적으로 추가를 할 수 있다. 거기다가 행 지향 데이터베이스는 데이터 검색을 고속화하기 위해 인덱스를 만드는데, 데이터 분석에서는 어떤 칼럼이 사용되는지 알 수 없기 때문에 인덱스를 만들어두어도 쓸모가 없다. 거기다가 대용량의 데이터 분석은 디스크 I/O를 동반하기 때문에 인덱스에 의지하지 않는 고속화 기술이 필요하다.
- 열 지향 데이터베이스
데이터 분석에서는 일부 칼럼만이 집계 대상이 된다. 그래서 열 지향 데이터베이스는 미리 데이터를 칼럼 단위로 정리를 해두어 필요한 칼럼만 가져올 수 있도록해서 디스크 I/O를 줄이게 한다. 그리고 열 지향 데이터베이스는 같은 값이 반복되는 데이터가 있을 수도 있으므로 데이터의 압축 효율도 굉장히 좋다.
3. MPP 데이터베이스의 접근 방식

책에 있는 그림, MPP 데이터베이스 행 지향 데이터베이스는 보통 하나의 쿼리를 하나의 스레드에서 실행한다. 그러면 여러 개의 CPU 코어를 사용하여 여러 개의 쿼리를 동시에 실행할 수 있다. 하지만 쿼리 하나가 분산 처리가 되는 것은 아니고, 하나의 쿼리는 빠르게 실행되기 때문에 분산 처리가 필요 없다.
열 지향 데이터베이스의 경우에는 대량의 데이터를 읽어오기 때문에 쿼리 1개의 실행 시간이 길다. 거기다가 위에서 언급했듯이 데이터를 압축하기 때문에 압축을 풀려면 CPU 리소스가 필요하므로 멀티 코어를 활용하여 쿼리 처리를 고속화하는 것이 좋다.
그래서 MPP 데이터베이스는 하나의 쿼리를 위 그림처럼 여러개의 작은 태스크로 분해하고 이를 최대한 병렬로 실행한다. 예를 들어 1억개의 레코드로 이루어진 테이블의 합계를 계산하려면 1,000개의 태스크로 나누어서 각 태스크마다 100,000개의 레코드의 합계를 동시에 구하게 만들어서 나중에 모든 결과를 모아 총합계를 계산하게 만든다.
- MPP 데이터베이스와 대화형 쿼리 엔진
쿼리를 잘 병렬화 했으면 MPP를 사용했을 경우 CPU 코어 수에 비례하여 고속화된다. 이때 디스크와 CPU 사이에 병목 현상이 발생하지 않도록 잘 분산해야 된다. MPP 데이터베이스는 고속화를 하기위해 구조상 하드웨어 수준에서 데이터 집계에 최적화를 시키고 SW와 HW를 일체화하였다. 그래서 시스템의 안정성이나 서포트 체제를 생각하면 상용 MPP 데이터베이스가 오랜 시간 사용해왔으니 성능은 보장되어 있다.
대화형 쿼리 엔진은 MPP의 아키텍처와 Hadoop을 같이 사용하는 것이다. 이런 경우에는 데이터를 분산 스토리지에 저장하는데, 데이터를 열 지향으로 압축을 해야 MPP 데이터베이스와 동등한 성능을 낼 수 있다. 그래서 Hadoop 상에서 열 지향 스토리지를 만드려고 하고 있다. 대화형 쿼리 엔진은 편리성쪽에서 MPP 데이터베이스보다 탁월한 능력을 가지고 있다.
두 개의 공통점은 무엇을 선택하든 둘 다 열 지향 스토리지로 변환해야한다는 것이다.
반응형'책 > 빅데이터를 지탱하는 기술' 카테고리의 다른 글
[빅데이터의 탐색] 4. 데이터 마트의 기본 구조 (0) 2022.03.23 [빅데이터의 탐색] 3. 애드 혹 분석과 시각화 도구 (0) 2022.03.23 [빅데이터의 탐색] 1. 크로스 집계의 기본 (0) 2022.03.23 [빅데이터의 기초 지식] 4. BI 도구와 모니터링 (0) 2022.03.22 [빅데이터의 기초 지식] 3. 파이썬 데이터 분석과 SQL 분석 (0) 2022.03.22