-
9일차(272 ~ 304)책/파이썬 라이브러리를 활용한 데이터 분석 2019. 3. 29. 19:08반응형
duplicated는 각 행이 이전에 나온 적이 있는지(중복 값인지) bool형으로 보여주는 명령어입니다.

책에 나와있는 data를 보면 위 사진과 같이 2행,5행,7행이 중복값입니다.
그래서 duplicated를 이용하면 다음과 같이 나오게 됩니다.

drop_duplicates는 duplicated배열이 False인 DataFrame을 보여주는 명령어입니다. unique와 비슷한 역할을 하는 명령어이네요.
drop_duplicates에 있는 keep인자는 중복되는 행을 제거할 때, 어떤 것을 제거할지 정해주는 인자입니다.
기본값은 keep=first로 각 중복 값중에서 처음 값을 남겨두고 나머지 행을 삭제합니다.
keep='last'는 각 중복 값중에서 마지막 값을 남겨두고 나머지 행을 삭제합니다.
keep=False는 남겨두는 것 없이 중복 값을 전부 삭제합니다.
str.lower는 Series/DataFrame안에 있는 index/column을 소문자로 변환시킵니다.
대문자는 str.upper입니다. str.title은 첫 알파벳만 대문자이고 나머지는 소문자로 변환시켜줍니다.
In[136]의 코드는 해석해보자면 columns에 'animal'을 추가시키는데, animal 열에 넣을 값은 'meat_to_animal' 값중에 'food'의 소문자형과 일치하는 값들을 넣겠다는 코드입니다.
cat이란 것은 categorical이라는 클래스 객체의 줄임말이라고 합니다. 보통 성별, 사회적 계급, 혈액형, 소속 국가 이런 것을 구할 때 주로 사용 된다고 하네요.
codes는 categories값중 어디에 위치하는지 보여주는 명령어입니다. index라고 생각하시면 됩니다.
categories는 categories를 반환하는 명령어입니다. index 명령어가 index를 반환하고, columns 명령어가 columns를 반환하듯이 이것도 같습니다.
단지 cat의 index는 codes라고 불리고, columns를 categories라고 불리는 것 같습니다.
cut은 실수 값의 경계선을 지정할 때 사용하는 명령어입니다. 출력물을 보면 (X,Y] 라는 것을 볼 수 있는데, 저건 X초과 Y이하라는 뜻입니다. [X,Y)가 되면 X이상 Y미만이 됩니다.
cut에 나오는 인자 right는 가장 오른쪽 부분을 포함할지 여부를 결정하는 인자라고 합니다. 기본 값은 True입니다.

labels 인자는 categories의 이름을 정해주는 인자입니다.
precision은 정밀도로 값들의 범위를 소수 x자리까지만 계산하고 나머지는 반올림 한다는 인자입니다.

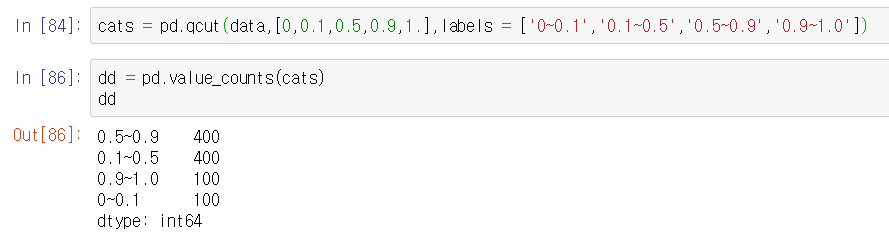
qcut 명령어는 어떤 균등분포내에서 x개의 그룹으로 나누는 명령어입니다.
qcut은 표준 변위치를 사용하기 때문에 적당히 같은 크기의 그룹으로 나눌 수 있다고 하네요.
pd.value_couts(cats)을 보니까 각각 250개씩, 4개 그룹으로 잘 나누어져있습니다.

qcut은 cut 명령어처럼 변위치를 직접 지정해줄 수도 있습니다. 값 범위는 0부터 1까지입니다.
get_dummies 명령어는 가변수를 만드는 명령어입니다.
-가변수란? https://rfriend.tistory.com/381
get_dummies의 인자인 prefix는 접두사로 columns 이름 앞에 접두사를 붙여주는 인자입니다.
join명령어에 있는 add_prefix는 index 이름에 접두사를 붙이는 인자입니다.
set.union이라는 것은 집합 자료형인 set으로 변환시킨 후 합집합을 구하는 명령어입니다.
너무 당연한 것인지 인터넷에 검색해봤는데 딱 한 곳에서만 언급해서 시간이 오래 걸렸습니다..
rfind는 마지막 부분 문자열의 첫 번째 글자의 위치를 반환하는 명령어라고 합니다. 뒤에서 부터 찾는 find함수라고 생각하시면 됩니다.
ljust / rjust는 문자열을 왼쪽/오른쪽으로 정렬하고, 길이가 남은 곳은 한 문자로 채워줍니다.(기본 값은 공백입니다.)

291쪽부터 정규표현식에 대한 내용이 나옵니다.
정규표현식에 대해 잘 모르는 분은 책부터 읽어보는 것보다 https://wikidocs.net/1669 부터 읽는 것을 추천드립니다.
그리고 나서 책을 읽으면 훨씬 더 이해하기 쉬울 것이라 생각됩니다.
292쪽 아래에 pattern = r'[A-Z0-9._%+-]+@[A-Z0-9.-]+\.[A-Z]{2,4}' 는 전자우표를 쓸 때 사용하는 정규식이라고 합니다.
296쪽에 마지막 코드는 그대로 따라하면 책과 다르게 나타나는 것을 확인할 수 있습니다.
str.match 명령어를 찾아보니 bool형으로 반환한다고 나와있는데 어떻게 저게 나오는지 모르겠네요;;

data.str[:5]를 제외하면 나머지도 제대로 작동이 안되는 것을 알 수 있습니다.
저는 정규표현식이라는 것을 이 책보고 처음알아서 어떻게 고쳐야할지 모르겠네요...
298쪽 7.5 예제: 미국 농무부 음식 데이터베이스 입니다.
파일은 usda_food에 적혀있는 database를 가져오면 됩니다.

참고로 In[282]: result부분에 'Zinc, Zn '이 나오는데 마지막 띄어쓰기를 하면 찾지 못하므로 'Zinc, Zn'으로 하면 됩니다.
반응형'책 > 파이썬 라이브러리를 활용한 데이터 분석' 카테고리의 다른 글
11일차(345 ~ 392) (0) 2019.04.02 10일차(305 ~ 344) (0) 2019.04.01 8일차(249 ~ 271) (0) 2019.03.28 7-2일차(219 ~ 247) (0) 2019.03.27 7-1일차(192 ~ 217) (0) 2019.03.27