-
[OS, Java] Zero Copy백엔드/Java 2024. 7. 31. 19:15반응형

올해 4월달쯤에 간단하게 공부하다가 넘어간 것 같은데, 이번에 제대로 공부할 기회가 생겼다.
Zero Copy는 CPU를 사용하지 않고, 디스크/메모리에 저장된 정보를 다른 메모리에 저장하는 방식으로 기존 전통적인 데이터 복사 방식보다 더 성능이 좋은 방식이다.
* 이번 내용은 운영체제 이론, 소켓에 대해 알고 있어야한다. (소켓 관련 글)
1. Zero Copy 이전에 사용하는 방법
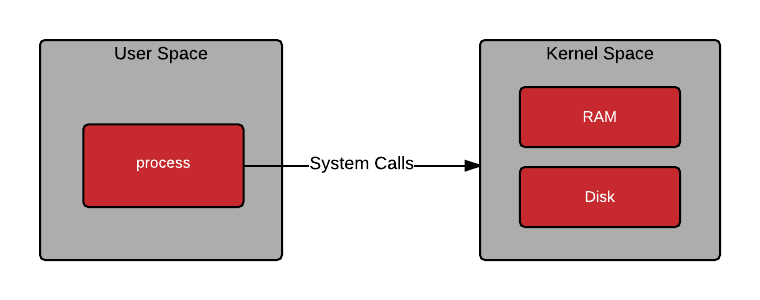
https://www.redhat.com/en/blog/architecting-containers-part-1-why-understanding-user-space-vs-kernel-space-matters 운영체제에서 사용자 - 커널 공간이 따로 나뉘어져 있는 그림을 많이 봤을 것이다. 코드를 동작할 때, 동작 원리를 깊숙히 들어가면 system call이 호출되는 형식이다. 데이터 복사도 마찬가지로 system call을 사용해서 유저 영역과 커널 영역을 넘나들게 된다.
데이터 복사에서 제일 많이 사용하는 곳은 여러가지가 있겠지만 대표적으로 소켓 통신이 있다. API 통신은 소켓을 통해 패킷을 송수신하게 되고, 데이터베이스도 연결한다면 데이터베이스의 SELECT, UPDATE, DELETE 등과 같은 명령어들도 소켓을 통해 작업이 이루어진다. 이때의 과정이 소켓에 있는 데이터를 buffer에 가져오게 되므로 데이터를 복사하게 된다. 왜냐하면 TCP / UDP와 같은 Transport Layer 영역부터는 커널이 관리하는 영역이기 때문이다.
만약 서버가 API 통신을 가정하고, 클라이언트에게 API 요청에 대한 응답을 보낸다고 가정하자
이때 응답값은 텍스트 파일에 있는 정보를 가져온다고 해보자
File.read(fileDesc, buf, len); Socket.send(socket, buf, len);위 코드는 File.read(...)를 통해 디스크에 저장된 텍스트 파일을 읽고, Socket.send(...)로 값을 보내는 과정이다.
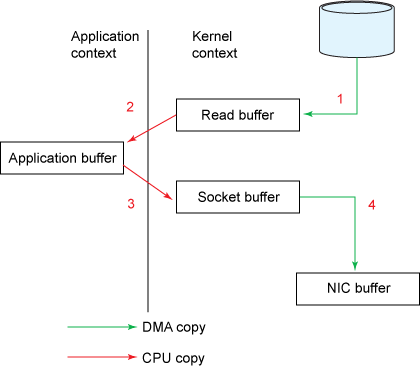
https://developer.ibm.com/articles/j-zerocopy/ * DMA copy는 Direct Memory Access로 CPU 연산 없이 메모리에 데이터를 읽고 쓸 수 있는 방법이다. 여기서는 디스크가 메모리에 적재하는 과정을 거친다.
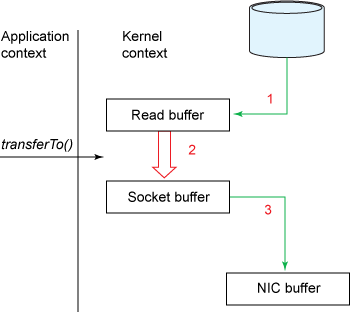
[1] read() 호출시 디스크에 저장된 값을 DMA를 통해 메모리의 Read buffer에 복사한다.
[2] Read buffer는 커널에 있으므로 사용자가 접근하지 못하기 때문에 Application buffer로 복사한다.
[3] send() 호출시 소켓을 통해 데이터를 보내야하므로 Application buffer 데이터를 Socket buffer로 복사한다.
[4] 패킷을 네트워크로 보내려면 NIC를 통해야하므로 NIC buffer로 복사한다. (NIC : Network Interface Card)
이렇게 데이터가 4번 복사된다.
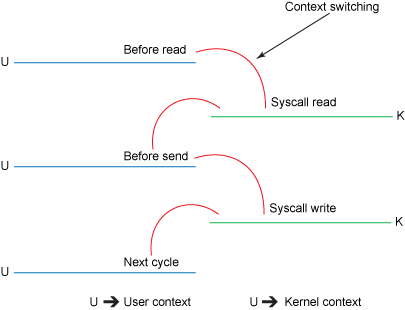
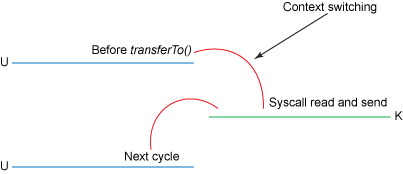
https://developer.ibm.com/articles/j-zerocopy/ 실제 성능 문제는 이 컨텍스트 스위칭에서 발생하게 된다.
[1 - 유저 → 커널] read() 호출
[2 - 커널 → 유저] 디스크에 있는 데이터를 DMA를 통해 Read buffer에 복사 후, Application buffer에 복사
[3 - 유저 → 커널] send() 호출
[4 - 커널 → 유저] Application buffer → Socket buffer → NIC buffer로 복사 후 컨텍스트 스위칭
이렇게 보면 명령어가 2개라서 최적화를 못한건가 생각이 들었는데, 여기에서도 각각 장점이 있었다.
첫 번째로 Read buffer가 일종의 Readahead Cache 기능을 한다고 한다.
이게 무슨 말일까?? 예를 들어서 Read buffer가 4KB라고 하고, read()에서 1KB만 읽는다고 할 때, 일단 디스크에 4KB 데이터를 Read buffer에 복사한다. 이후 read()가 이후 추가적인 1KB를 요청한다면 Read buffer에 이미 데이터가 존재하기 때문에 캐시처럼 동작하게 된다는 것이다.
두 번째로 Socket buffer는 비동기 처리가 가능하다고 한다.
만약 Application buffer → NIC buffer로 간다고 하면 사용자 입장에서는 블로킹 상태가 된다. 하지만 비동기 처리가 가능하게 된다면 Application buffer → Socket buffer로 복사하기만 해도 완료되었다고 처리할 수 있다. 이후엔 커널이 알아서 비동기로 처리하면 되는 것이다. 잘 와닿지 않는다면 NIC buffer 대신 시간이 오래 걸리는 디스크에 저장한다고 생각해보자. 유저 → 디스크로 다이렉트로 저장하게된다면 디스크에 파일이 저장될 때까지 기다려야하는 블로킹이 된다.
하지만... 이것도 결국 한계점은 있었다
Readahead Cache의 전제 조건은 (Read Buffer 크기) > (사용자 요청 데이터)일 때 얻을 수 있는 장점이라는 것이다. 하지만 요즘 데이터는 한 번의 요청에 Read buffer 한 번으로도 충분하지 않은 경우가 있기 때문에 성능 병목이 발생해버렸다.
2. Zero Copy
[1] 불완전한 제로 카피
File.read(fileDesc, buf, len); Socket.send(socket, buf, len);제로 카피는 어디를 개선할 수 있을까?? 생각해보면 우리가 작성하는 코드는 위와 같이 File.read(...), Socket.send(...)로 서로 연속된 코드를 작성하고 있다. 최적화한다면 read()와 send()를 하나로 합칠 수도 있다는 점이다.
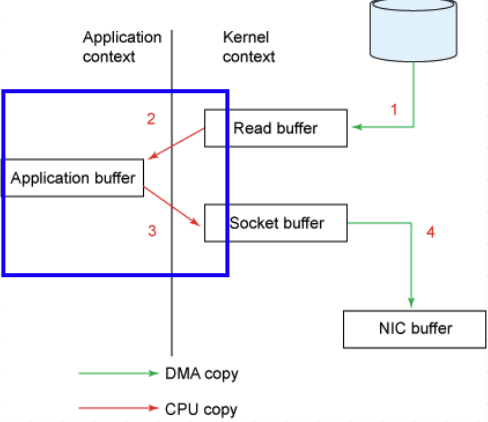
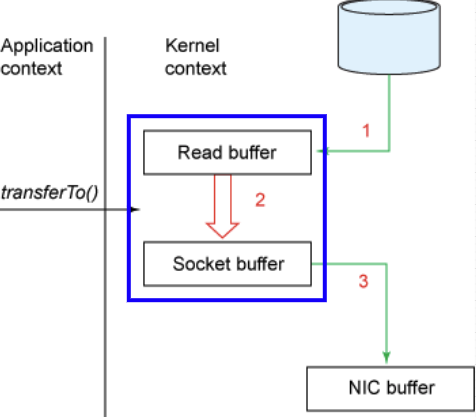
명령어를 하나로 합친다면 파란 네모박스의 2, 3 과정이 없어진다. 이 말은 중간 과정에 발생하는 두 번의 컨텍스트 스위치가 사라지게 된다.
#include <sys/socket.h> ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count); 참고 링크: https://man7.org/linux/man-pages/man2/sendfile.2.htmlLinux에서는 sendfile 이라는 것을 지원해준다.
public abstract long transferTo(long position, long count, WritableByteChannel target); public abstract long transferFrom(ReadableByteChannel src, long position, long count);자바의 NIO에서는 transferTo(), transferFrom()을 지원해준다.
그래서 동작 과정은 디스크 → Read buffer → Socket buffer → NIC buffer로 동작하게 된다. 데이터 복사는 4번 → 3번으로 줄어들고, 복사 과정에서 CPU 연산은 2회 → 1회로 사용된다. 거기다가 컨텍스트 스위치는 유저 → 커널 → 유저로 두 번만 일어나게 된다.
여기까지만 해도 이전 방식보다 더 좋은 성능을 낼 수 있지만, 더 최적화를 할 수 있었다.
게다가 제로 카피라는 말은 CPU를 전혀 사용하지 않고 복사를 하는 방법이다.
[2] 완전한 제로 카피
사용자는 sendfile(...), transferTo(...), transferFrom(...)을 사용하는 것은 그대로인데, 내부 동작 과정이 바뀌게 되어 제로 카피가 완성되었다.

https://www.micahlerner.com/2021/07/07/breakfast-of-champions-towards-zero-copy-serialization-with-nic-scatter-gather.html IBM 문서에서 NIC가 gather 연산을 지원하게 되어 내부 동작이 바뀌었다는데, gather 연산이 어떤 역할인지 찾아보니 정확한 이름은 scatter-gather로 분산 수집이라는 뜻을 가지고 있다. 분산 수집 기능이 없었을 때는 이전까지 분산된 데이터를 Socket buffer라는 곳에 하나로 모아서 NIC buffer로 보내야 했다. 간단하게 이야기하면 연속된 메모리 주소를 가져야 DMA copy를 할 수 있었다는 점이다. 하지만 기술 발전에 따라 scatter-gather가 나오게 됐고, 이후 하드웨어 발달로 인해 NIC 카드가 scatter-gather 연산을 지원하게 되어 비연속적인 주소에 저장된 데이터들을 NIC가 처리할 수 있게 되었다. (scatter-gather에 대한 자세한 내용은 맨 아래 참고한 링크 확인)
이것을 통해 위 사진의 파란 박스도 사라지게 되어 CPU는 데이터 복사에서 해방됐다.
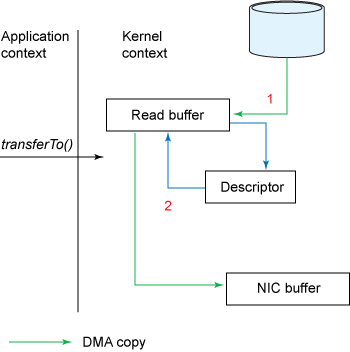
대신 디스크립터가 새로 생겼는데, Socket buffer에 데이터를 직접적으로 복사하는 것이 아닌 Descriptor를 통해 어느 곳에 어느 크기의 데이터가 있는지 간접적으로 확인할 수 있게 된다. NIC buffer에 scatter-gather 방식으로 데이터를 보내줄 수 있게 됐고, CPU가 데이터 복사에서 할 일이 없어지게 됐다.
[3] 성능 비교
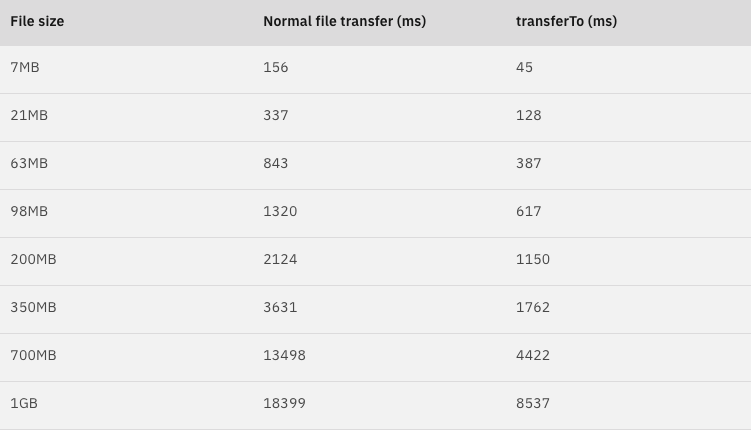
기본적으로 두 배 이상 차이난다.
이외에도 Apache Kafka에 제로 카피가 적용되어 있어서 카프카를 사용하는 많은 이유중에 하나라고 한다. 이와 반대로 Apache Kafka 다음으로 많이 쓰이는 RabbitMQ는 안정성을 중시하기 때문에 제로 카피는 사용하지 않는다고 한다. Apache Pulsar는 깃허브 PR을 찾아보니 제로 카피를 일부 지원하고 있다.
참고한 링크
글은 1번 내용을 기반으로 작성했다. 부족한 부분은 2번 ~ 5번 내용을 참조했다.
DMA copy에 대해 더 궁금하신 분은 4번, 5번을 읽어보는걸 추천하고, 자바 NIO에 대해 더 궁금하신 분은 6번을 읽어보는걸 추천한다.
1. IBM Developer - Efficient data transfer through zero copy
2. Linux Kernel Documentation - MSG_ZEROCOPY
3. LWN net - Zero-copy networking
4. yohda 블로그 - [리눅스 커널] DMA - overview
5. LWN net - Scatterlist chaining
6. Mark Kim 블로그 - 사례를 통해 이해하는 네트워크 논블로킹 I/O와 Java NIO
반응형'백엔드 > Java' 카테고리의 다른 글
[Java] ReentrantLock (0) 2024.07.22 [Concurrency] Actor Model (0) 2024.05.07 [Concurrency] Software Transactional Memory (Beautiful concurrency) (0) 2024.04.29 [Java, Concurrency] Compare and Swap 알고리즘 (CAS) (0) 2024.04.14 [Java] @BeforeAll과 static block의 차이 (0) 2023.03.01